Python3 爬虫(十五):Scrapy 基础之 CrawlSpider
Scrapy基础-CrawlSpider类
在之前的Scrapy基础之Pipeline中,已经可以简单的使用Spider类来对所需要的网站中的数据进行爬取。Spider基本上能做很多事情了,但是假如想要爬取某一个网站全站数据的话,Spider可能需要进行一些相应的处理才能胜任这项工作,因此你可能需要一个更强大的武器——CrawlSpider。
CrawlSpider基于Spider,但是可以说是为全站爬取而生。
CrawlSpider
CrawlSpider 是爬取那些具有一定规则网站的常用爬虫,它基于 Spider 并添加了一些独特的属性
CrawlSpider 与 Spider 类的最大不同是多了一个 rules 参数,其作用是定义网页中链接的提取动作。在 rules 中包含一个或多个 Rule 对象,Rule 类与 CrawlSpider 类都位于 scrapy.spiders 模块中。
Rule对象
Rule对象的定义如下
class scrapy.spiders.Rule(link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None)
各个参数的定义如下:
- link_extractor:是一个Link Extractor对象,用来确定请求响应中的哪些链接是需要被提取的。
- callback:回调函数名,字符串类型,用来指定当请求响应返回时处理的函数
- cb_kwargs:传入回调函数的关键字参数字典
- follow:boolean类型,表明是否对网页进行深度爬取,没有指定回调函数时默认为True,其余情况默认为False
一般来说在爬虫项目中只需要指定 link_extractor 和 callback 以及 follow 属性的值即可。
callback是指定一个自定义的请求响应处理函数,注意该函数的名称不能是 parse ,因为 CrawlSpider 实现使用到了 parse,假如指定为 parse会导致 CrawlSpider 无法正常运行。
而 link_extractor 是一个 LinkExtractor 对象,下来看一下该对象。
LinkExtractor对象
LinkExtractor 对象是 scrapy.linkextractors 模块下的一个类,其实就是LxmlLinkExtractor具体的定义为:
class scrapy.linkextractors.lxmlhtml.LxmlLinkExtractor(allow=(), deny=(), allow_domains=(), deny_domains=(), deny_extensions=None, restrict_xpaths=(), restrict_css=(), tags=('a', 'area'), attrs=('href', ), canonicalize=False, unique=True, process_value=None, strip=True)
主要的参数为:
- allow:满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。
- deny:与这个正则表达式(或正则表达式列表)不匹配的URL一定不提取。
- allow_domains:会被提取的链接的domains。
- deny_domains:一定不会被提取链接的domains。
- restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接。还有一个类似的restrict_css
CrawlSpider工作原理
因为 CrawlSpider 继承了 Spider,所以其具有 Spider 的所有函数。
CrawlSpider在运行时首先由 start_requests 对 start_urls 中的每一个 url 发起请求(make_requests_from_url),这个请求会被 parse 接收(在 Spider 里面的 parse 需要我们定义),CrawlSpider 定义 parse 去解析响应(self._parse_response(response, self.parse_start_url, cb_kwargs={}, follow=True))
_parse_response 则根据有无 callback,follow 和 self.follow_links 执行不同的操作
def _parse_response(self, response, callback, cb_kwargs, follow=True):
"""
如果传入了callback,使用这个callback解析页面并获取解析得到的reques或item
"""
if callback:
cb_res = callback(response, **cb_kwargs) or ()
cb_res = self.process_results(response, cb_res)
for requests_or_item in iterate_spider_ou(cb_res):
yield requests_or_item
"""
其次判断有无follow,用_requests_to_follow解析响应是否有符合要求的link
"""
if follow and self._follow_links:
for request_or_item in self._requests_to_follow(response):
yield request_or_item
其中 _requests_to_follow 又会获取 link_extractor(这个是我们传入的LinkExtractor)解析页面得到的link (link_extractor.extract_links(response)),来对url进行处理process_links(需要自定义),对符合的 link 发起 Request请求。使用 process_request (需要自定义)处理响应。
CrawlSpider获取rules
CrawlSpider 类会在 __init__ 方法中调用 _compile_rules方法,然后在其中浅拷贝 rules 中的各个 Rule 来获取要用于回调(callback)中要进行处理的链接(process_links)和要进行的处理请求(process_request)
def _compile_rules(self):
def get_method(method):
if callable(method):
return method
elif isinstance(method, six.string_types):
return getattr(self, method, None)
self._rules = [copy.copy(r) for r in self.rules]
for rule in self._rules:
rule.callback = get_method(rule.callback)
rule.process_links = get_method(rule.process_links)
rule.process_request = get_method(rule.process_request)
那么Rule是怎么样定义的呢?
class Rule(object):
def __init__(self, link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=identity):
self.link_extractor = link_extractor
self.callback = callback
self.cb_kwargs = cb_kwargs or {}
self.process_links = process_links
self.process_request = process_request
if follow is None:
self.follow = False if callback else True
else:
self.follow = follow
因此会将 LinkExtractor 传递给 link_extractor。
使用 CrawlSpider 来爬取腾讯招聘网站全站的数据
网站分析
腾讯招聘是腾讯面向社会各界招聘信息的展示平台,目前共有3011条招聘信息。
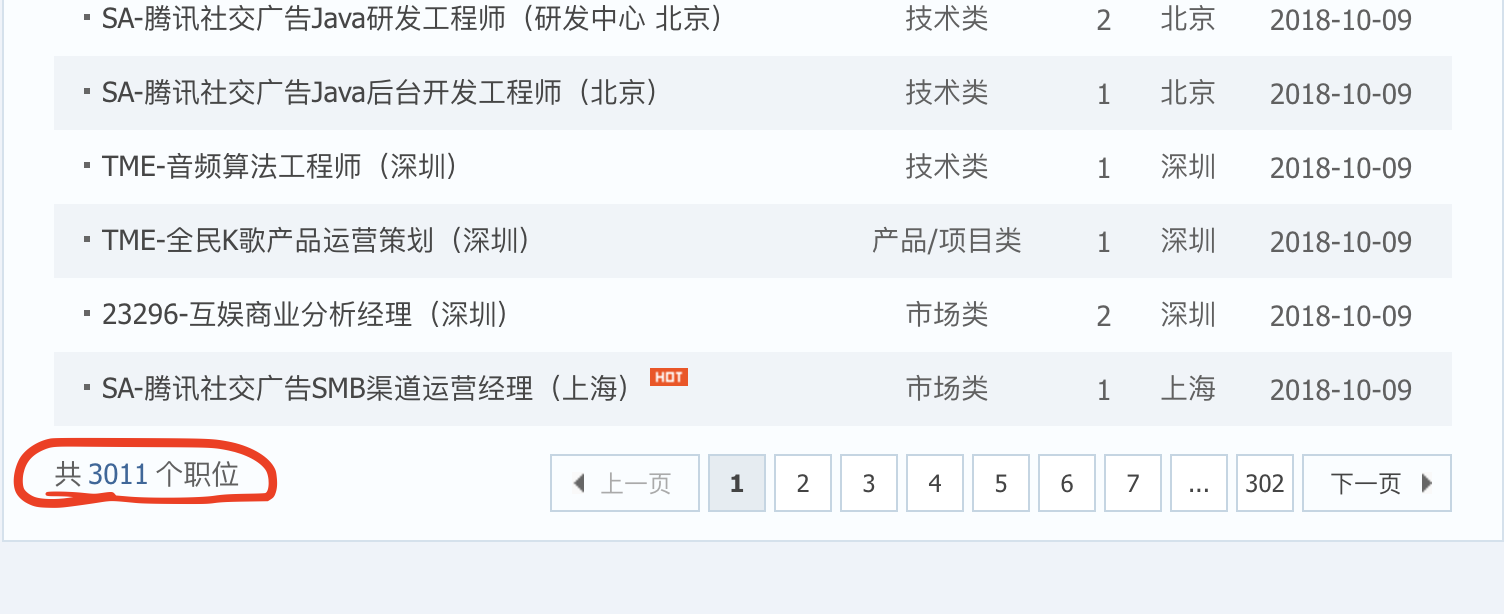
分析其网站结构,我们主要想要获取的信息是每一页中的职位名称,职位详情链接,职位类型,需求人数,工作地点,发布时间。这些可以通过 xpath来进行获取。然后在获取下一页的信息。
分析网页中的链接可以发现其下一页的链接都是 href=”position.php?&start=10#a”,那么对应的正则匹配表达式就为 start=\d+。
接下来便开始创建对应的 scrapy爬虫项目。
创建项目
scrapy startproject tencentCrawlSpider
cd tencentCrawlSpider/tencentCrawlSpider/spiders
scrapy genspider -t crawl tencent tencent.com
以上便创建了一个初始化的 scrapy项目,并且创建了一个使用 crawl 模版的基本 spider类。接下来分别编写对应的文件信息。
items.py
import scrapy
class TencentcrawlspiderItem(scrapy.Item):
# define the fields for your item here like:
# 职位名称
position_name = scrapy.Field()
# 职位详情链接
position_url = scrapy.Field()
# 职位类型
position_type = scrapy.Field()
# 需求人数
people_num = scrapy.Field()
# 工作地点
position_addr = scrapy.Field()
# 发布时间
position_time = scrapy.Field()
pipelines.py
import json
class TencentspiderPipeline(object):
"""
处理爬虫所爬取到的数据
"""
def __init__(self):
"""
初始化操作,在爬虫运行过程中只执行一次
"""
self.file = open('tencent_position.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 现将item数据转为字典类型,再将其保存为json文件
text = json.dumps(dict(item), ensure_ascii=False)+'\n'
# 写入本地
self.file.write(text)
# 会将item打印到屏幕上,方便观察
return item
def close_spider(self, spider):
"""
爬虫关闭时所执行的操作,在爬虫运行过程中只执行一次
"""
self.file.close()
spiders/tencent.py
# -*- coding: utf-8 -*-
import scrapy
# 负责对响应中的链接进行处理
from scrapy.linkextractors import LinkExtractor
# 导入对应的CrawlSpider 和 Rule(负责发送请求)
from scrapy.spiders import CrawlSpider, Rule
# 导入对应的item对象
from tencentCrawlSpider.items import TencentcrawlspiderItem
class TencentSpider(CrawlSpider):
name = 'tencent'
allowed_domains = ['tencent.com']
# 初始访问页面,直接指定确定的页面
start_urls = ['https://hr.tencent.com/position.php?start=0']
# 响应页面中链接匹配规则(正则表达式)
link_list = LinkExtractor(allow=r'start=\d+')
# 将页面中获取到的链接交付给调度器队列去下载,并指定响应的处理回调函数
# 可以指定多个匹配规则的rule,这样会发送多种不同的请求
# follow为是否开启深度爬虫
rules = (
Rule(link_list, callback='parse_item', follow=True),
)
def parse_item(self, response):
"""
对下载器返回的响应进行处理的函数
"""
# 获取当前页面所有的职位信息
positions = response.xpath('//tr[@class="even"]|//tr[@class="odd"]')
# 对页面的数据进行处理
for position in positions:
# 创建一个item对象
item = TencentcrawlspiderItem()
# 将item中的各属性进行设置
item['position_name'] = position.xpath('./td[1]/a/text()')[0].extract()
item['position_url'] = position.xpath('./td[1]/a/@href')[0].extract()
# 注意有些岗位没有职位名称,因此得做一些相应的判断
if len(position.xpath('./td[2]/text()')) > 0:
item['position_type'] = position.xpath('./td[2]/text()')[0].extract()
item['people_num'] = position.xpath('./td[3]/text()')[0].extract()
item['position_addr'] = position.xpath('./td[4]/text()')[0].extract()
item['position_time'] = position.xpath('./td[5]/text()')[0].extract()
# 将item发送给pipeline去处理
yield item
setting.py
# -*- coding: utf-8 -*-
BOT_NAME = 'tencentCrawlSpider'
SPIDER_MODULES = ['tencentCrawlSpider.spiders']
NEWSPIDER_MODULE = 'tencentCrawlSpider.spiders'
# 指定日志保存路径和保存级别
LOG_FILE = "tencent_log.log"
LOG_LEVEL = "DEBUG"
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko'
}
ITEM_PIPELINES = {
'tencentCrawlSpider.pipelines.TencentspiderPipeline': 300,
}
运行爬虫,爬取数据
启动爬虫
scrapy crawl tencent
成功的爬取到了所有的数据

查看作者信息
