Python3 爬虫(十三):Scrapy 基础之 Pipeline
Pipeline
Pipeline 是 scrapy 框架中专门对爬虫爬取的数据进行处理的组件。
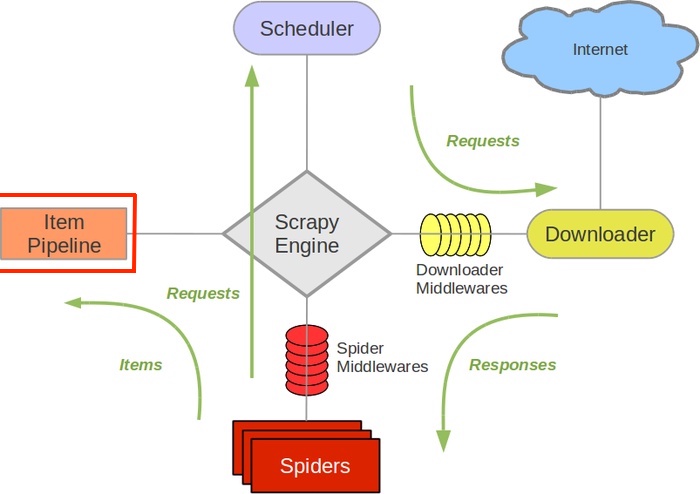
如上图所示,一个 scrapy 项目中主要的数据流向。其中最主要的是以 spider 爬虫为中心的数据走向,spider 将请求信息发送给 download,而将 items 数据信息是发送给 item Pipeline 去处理的。
首先我们知道,爬虫所爬取的数据是要交给一个对应的 item对象进行保存的,这个item对象是根据网站上所需要爬取的数据决定的,只需定义对应的名称即可,不需要定义格式。
在爬虫将网页上的数据封装为一个对应的item文件之后是需要使用 yield来将其发送给 pipeline来进行处理。所以说,在一个 scrapy项目中真正处理数据的是pipeline。
Pipeline 使用
首先我们得了解到创建一个 scrapy 爬虫项目的主要流程:
-
创建项目
-
配置setting文件
-
分析网页数据,编写items文件
-
编写爬虫,爬取数据
-
编写pipeline文件,处理item数据
-
启动项目
所以说,我们的 pipeline 文件是要根据我们的 item 文件定义的格式来进行编写的。
pipeline 文件位于项目中 pipelines.py 文件中,一个简单的 pipeline 文件的格式如下:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class SomePipeline(object):
def process_item(self, item, spider):
pass
可以看到,该类就是一个简单的对象类,继承自 object 父类,类中有一个默认的方法 process_item 是必须要写的。可以看到该方法接收两个参数 item 和 spider,其中 item 便是从爬虫返回过来的。可以在该方法中对 item 中保存的数据进行处理。
在项目中使用 pipeline 处理数据之前,首先得修改配置文件,将对应的 pipeline 设置到项目中去。
# 要使用pipeline来处理item的数据时必须在这里进行设置,后面的数字为优先级,假如有多个pipeline时按照优先级高低进行处理
ITEM_PIPELINES = {
'firstSpider.pipelines.SomeSpiderPipeline': 300,
}
实例:获取 itcast.cn 中所有的教师信息
分析
首先观察 itcast页面,可以看到该网页静态的展示了所有的教师信息,其中不同科目的教师信息是以 # 进行区分,因此我们只要爬取这一页的数据即可。
可以看到网页显示的老师信息主要包括:教师名字、头像、职位、简介。因此我们可以使用 xpath 来分别解析这些信息:
所对应的匹配规则如下:
# 老师信息匹配内容:
//div[@class="li_txt"]
# 老师姓名匹配内容:
./h3/text()
# 老师职位匹配内容:
./h4/text()
# 老师描述信息匹配内容:
./p/text()
知道了所需要获取的数据之后便可以开始动手写代码了。
创建项目
首先创建一个对应的 scrapy 项目
python3 -m scrapy stratproject itcastSpider
创建完项目之后进行其 spiders 文件夹,生成对应的 spider文件,生成 spider 的时候在后面可以指定所需要访问的网址
cd itcastSpider/itcastSpider/spiders
python3 -m scrapy genspider itcast_teacher_spider 'http://www.itcast.cn/channel/teacher.shtml'
这样,一个 scrapy 项目便创建好了。
首先,先来编写 items 文件
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ItcastTeacherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 老师姓名
name = scrapy.Field()
# 老师职位
position = scrapy.Field()
# 老师描述信息
info = scrapy.Field()
接下来编写对应的爬虫文件 /spiders/itcast_teacher_spider.py
import scrapy
from firstSpider.items import ItcastTeacherItem
class ItcastSpider(scrapy.Spider):
"""
scrapy爬虫类,用来爬取数据
"""
name = "itcast"
# 爬取范围
allowd_domains = ["http://www.itcast.cn/channel/teacher.shtml"]
# 需要爬取的网页列表,注意有#的网页可以不用管
start_urls = ["http://www.itcast.cn/channel/teacher.shtml"]
def parse(self, response):
"""
开始对网页进行解析,并将获取的数据保存到本地
:param response:
:return:
"""
# 从网页中获得的老师数据
teachers = response.xpath('//div[@class="li_txt"]')
# 创建一个数组来将所有的教师信息保存
# itcast_teachers = []
# 开始处理每一页的教师信息
for teacher in teachers:
# 创建一个保存老师信息的item实例
item = ItcastTeacherItem()
# 必须将解析的内容使用extract方法解析为unicode编码
name = teacher.xpath('./h3/text()')[0].extract()
position = teacher.xpath('./h4/text()')[0].extract()
info = teacher.xpath('./p/text()')[0].extract()
# 将信息保存到item中
item["name"] = name
item["position"] = position
item["info"] = info
# 将保存的信息通过yield的方式交给pipeline去处理
yield item
接下来来编写对应的管道处理文件 pipeline.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
class ItcastSpiderPipeline(object):
"""
处理在爬虫中返回的item数据的类,将传递过来的数据进行永久化
"""
def __init__(self):
"""
初始化类中所需的数据,可选操作
"""
# 创建了一个文件,将文件的保存类型设置为utf-8
self.file = open('teachers.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
"""
对item数据进行处理的方法,该方法必须要写,参数固定
:param item:
:param spider:
:return:
"""
# 将数据由列表格式先变换为字典格式,再变换为json格式的数据
json_text = json.dumps(dict(item), ensure_ascii=False)+"\n"
# 保存数据为utf-8的格式
self.file.write(json_text)
def close_spider(self, spider):
"""
爬虫关闭时执行的函数,可选操作,可以用来对资源进行回收
:return:
"""
self.file.close()
接下来还得修改项目的配置信息 settings.py 文件,主要是将 pipeline 文件配置好
ITEM_PIPELINES = {
'firstSpider.pipelines.ItcastSpiderPipeline': 300,
}
最后启动项目
python3 -m scrapy crawl itcast
查看作者信息
