Python3 数据科学(四):Matplotlib
Matplotlib 入门
Matplotlib 是一个 Python 2D绘图库,可以生成各种样式的数据图形,包括折线图、散点图、柱状图、饼图等。 Matplotlib 可用于 Python 脚本,Python 和 IPython shell,Jupyter notebook,Web 应用程序服务器和四个图形用户界面工具包。
本文所用到的数据下载地址
安装 Matplotlib
推荐使用 pip 来直接安装:
pip install matplotlib
Matplotlib 使用
其实学习 Matplotlib 最快速的方式是学习官网给出的示例图,基本上日常需要的图在官网上都能够找到。官网地址:https://matplotlib.org/gallery/index.html
Matplotlib 导入
在使用 Matplotlib 之前首先得将其导入到我们的工作环境中来:
import matplotlib.pyplot as plt
折线图绘制
折线图是排列在工作表的列或行中的数据可以绘制到折线图中。 折线图可以显示随时间(根据常用比例设置)而变化的连续数据,因此非常适用于显示在相等时间间隔下数据的趋势。 在折线图中,类别数据沿水平轴均匀分布,所有值数据沿垂直轴均匀分布。
首先导入我们所需要绘制的图像数据:
import pandas as pd
unrate = pd.read_csv('./data/unrate.csv')
# 将时间数据转换为 datetime 类型
unrate['DATE'] = pd.to_datetime(unrate['DATE'])
unrate.head()
我们这里使用的数据是美国历年的失业率的一个统计数据,是从1948年到2016年的每月的失业率调查结果。
接下来我们需要首先先来认识到 plt 当中最重要的一个函数 plot(),这个函数是用将所给的数据绘制成图像的。
matplotlib.pyplot.plot(*args, scalex=True, scaley=True, data=None, **kwargs
以下的代码就绘制了一个空白的图像,因为并没有传入任何的数据
plt.plot()
但是只执行上面的代码并没有任何的结果展示出来,这是因为使用 plot 绘制的图像必须得调用 .show()方法才会显示出来:
plt.show()
这样便显示出来结果:
这只是简单的创建了一个空白的图像,我们可以给这个图像传入一些相应的数据以及图像样式。并且还可以指定图像的一些配置信息:
# 将数据集中的前十二行取出,也就是1948年的所有月份的数据
first_10 = unrate[0:12]
# 将date做为x轴数据,value做为y轴数据,传入相对应的参数,可以指定线的颜色,形状,格式
plt.plot(first_10['DATE'],first_10['VALUE'],'r')
# 以下可以对图像进行一些相应的调整
# 将横坐标进行45度旋转
plt.xticks(rotation=45)
# 横坐标标签
plt.xlabel('Month')
# 纵坐标标签
plt.ylabel('Unemployment Rate')
# 图像标题
plt.title('Monthly Unemployment Trends, 1948')
# 将图像展示出来
plt.show()
显示结果为:
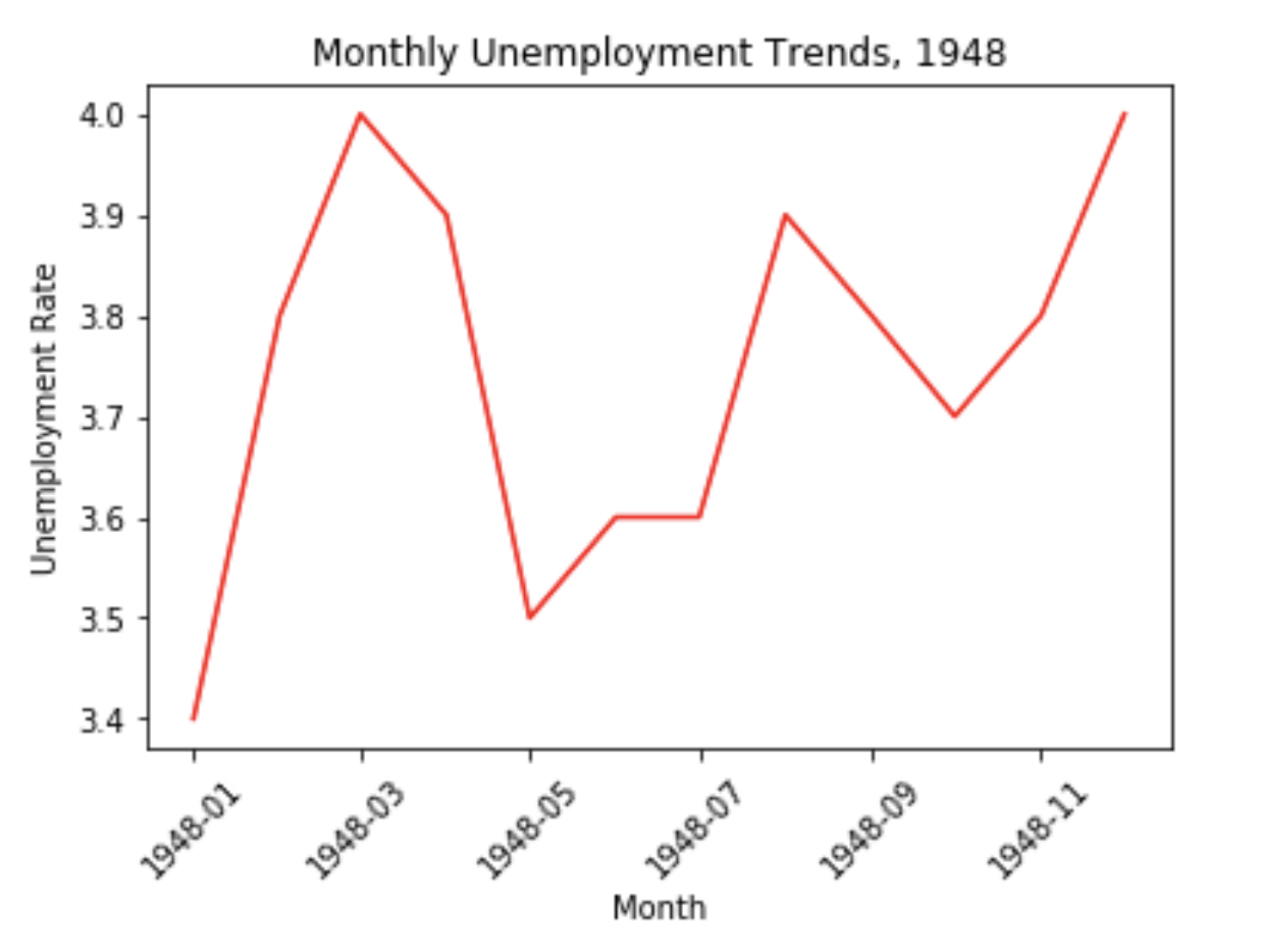
注意,我在 plot 函数中不仅传入了对应的 x 和 y 的数据,而且还传入了一些指定的曲线样式,这样样式是由以下组成的:
颜色样式
- ‘b’:蓝色
- ‘g’:绿色
- ‘r’:红色
- ‘c’:青色
- ‘m’:品红
- ‘y’:黄色
- ‘k’:黑色
- ‘w’:白色
基本上这些就够我们正常的画图使用了,当然也可以使用自定义的 RGB 三色值来指定颜色,这就得使用 matplotlib.colors函数了。
数据标记样式
- ’.’:point marker
- ’,’:pixel marker
- ‘o’:circle marker
- ‘v’:triangle_down marker
- ’^’:triangle_up marker
- ’<’:triangle_left marker
- ’>’:triangle_right marker
- ‘1’:tri_down marker
- ‘2’:tri_up marker
- ‘3’:tri_left marker
- ‘4’:tri_right marker
- ’s’:square marker
- ‘p’:pentagon marker
- ‘*‘:star marker
- ‘h’:hexagon1 marker
- ‘H’:hexagon2 marker
- ’+’:plus marker
- ‘x’:x marker
- ‘D’:diamond marker
- ‘d’:thin_diamond marker
-
’ ‘:vline marker - ‘_‘:hline marker
曲线样式
- ’-‘:实线
- ’–‘:直虚线
- ’-.’:点划线
- ’:’:点虚线
以上的这些样式配置可以组合使用,比如:
- ‘r–‘:红色直虚线
plt.plot(first_10['DATE'],first_10['VALUE'],'r--')
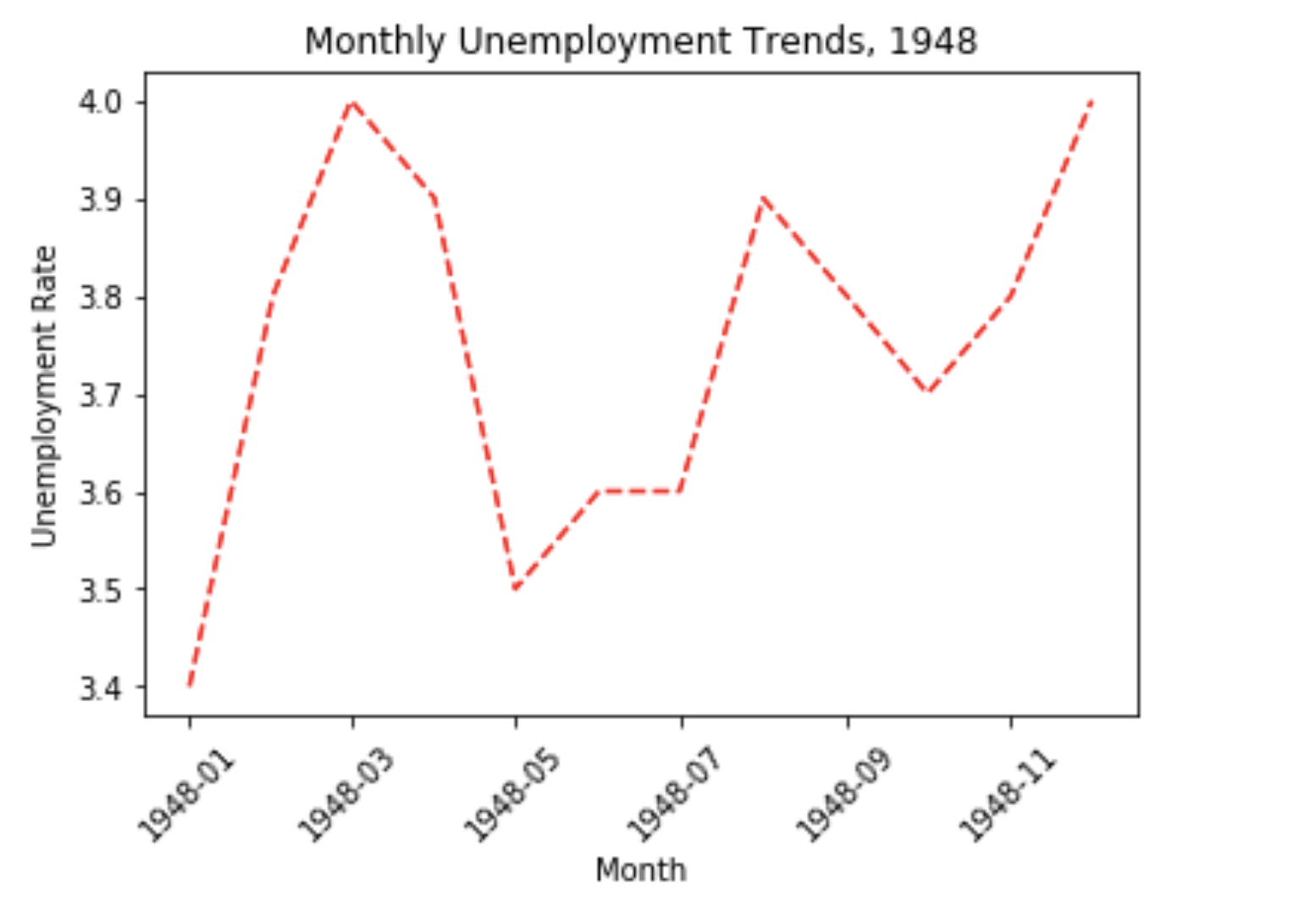
- ‘k.’:黑色点状图
plt.plot(first_10['DATE'],first_10['VALUE'],'k.')
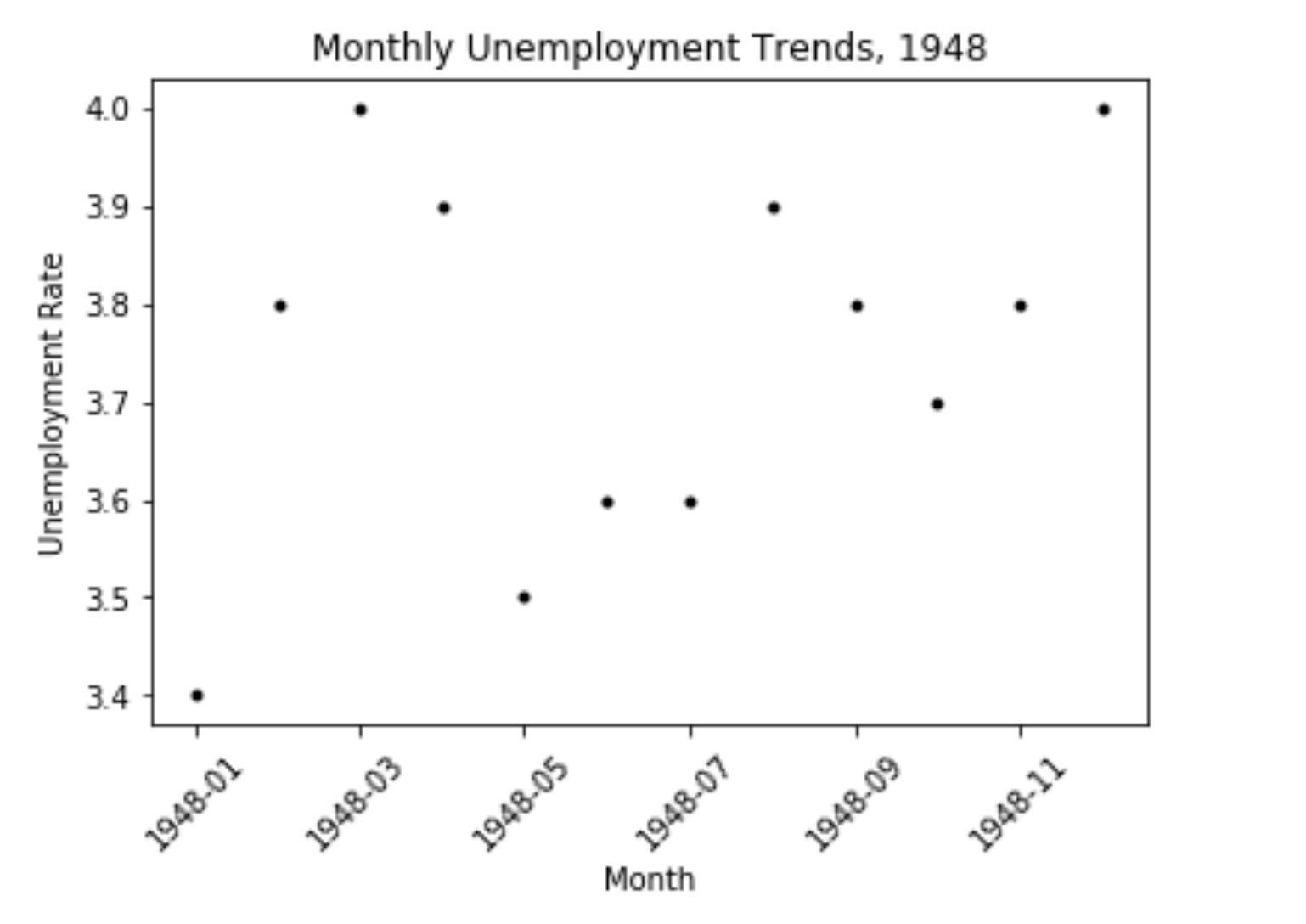
等等,可以自己随意搭配。
多折线图绘制
这里就得介绍 plt 中的另一个函数 figure
class matplotlib.figure.Figure(figsize=None, dpi=None, facecolor=None, edgecolor=None, linewidth=0.0, frameon=None, subplotpars=None, tight_layout=None, constrained_layout=None)
详细的参考文献
通过 plt.figure() 可以创建一个 Figure 类,通过这个类便可以创建一个画图对象,实现更加复杂的画图操作,例如可以指定当前的图像的大小或创建多个子图。
创建子图
创建子图的意思是在当前的一个大的绘图区域内显示多个小的图像,这些小的图像称之为子图。
使用 add_subplot(m,n,i)方法来创建子图。m 表示创建 m 行子图,n 表示创建 n 列子图,而 i 是子图的序号,从1开始,按照从左往右,从上到下的顺序来排序。
# 创建一个figure对象
fig = plt.figure()
# 创建每一个绘图轴
ax1 = fig.add_subplot(2,2,1)
# ax2 = fig.add_subplot(2,2,2)
ax2 = fig.add_subplot(2,2,3)
ax2 = fig.add_subplot(2,2,4)
# 显示图像
plt.show()
显示结果:
多折线图
# 对数据集进行提取
unrate['MONTH'] = unrate['DATE'].dt.month
# 创建figure对象,可以指定大小
fig = plt.figure(figsize=(12,5))
# 指定颜色列表,区分不同的曲线
colors = ['red', 'blue', 'green', 'orange', 'black']
# 使用循环来绘制多条曲线
for i in range(5):
# 获取数据集
subset = unrate[i*12:(i+1)*12]
# 显示每条曲线的标签
label = str(1948+i)
# 开始绘制每条曲线
plt.plot(subset['MONTH'], subset['VALUE'], c=colors[i], label=label)
# 将曲线的 label 放置到一个指定的位置上
plt.legend(loc='best')
# 横坐标标签
plt.xlabel('Month')
# 纵坐标标签
plt.ylabel('Unemployment Rate')
# 图像标题
plt.title('Monthly Unemployment Trends, 1948-1952')
# 显示图像
plt.show()
显示结果:
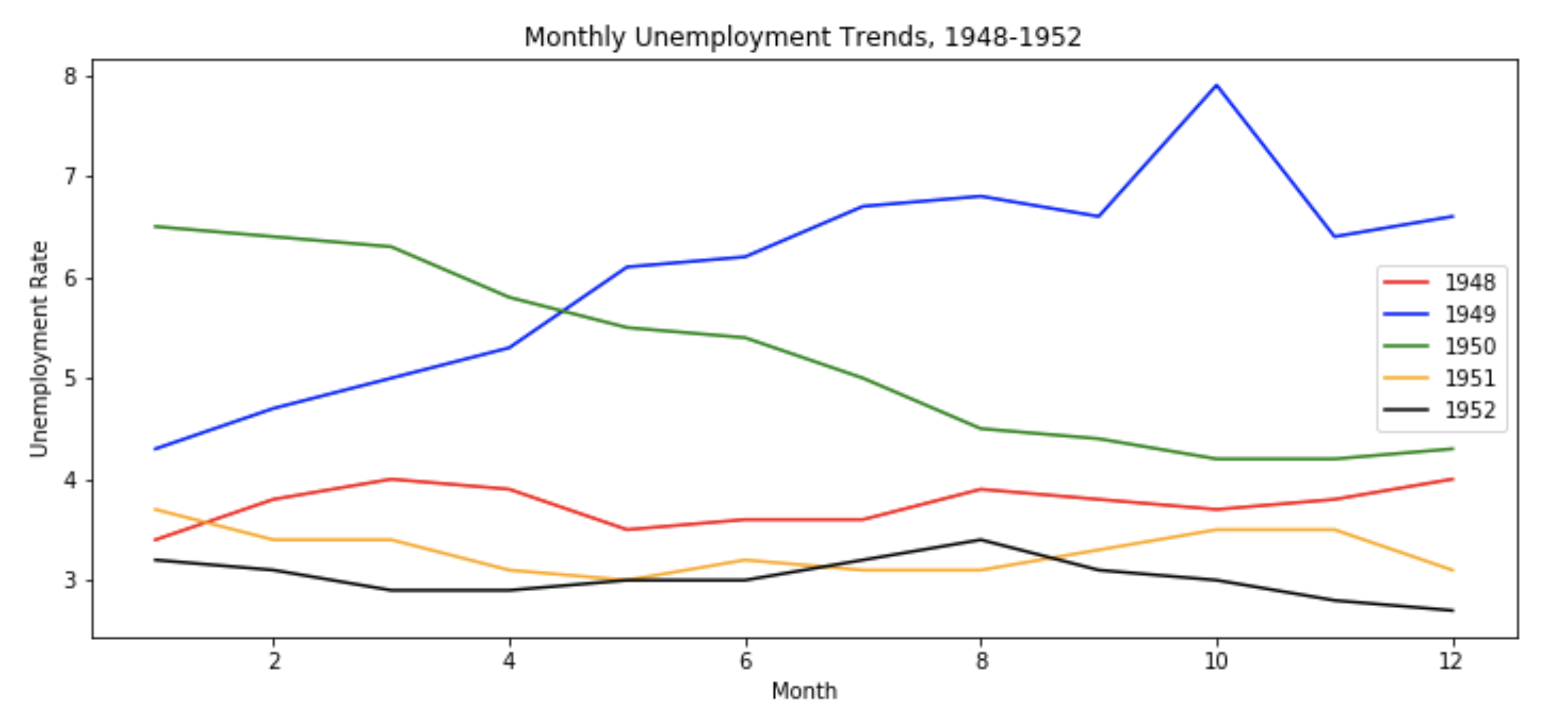
其中的 legend方法中指定的 loc属性是指曲线的 label 放置的位置,可以有如下的取值:
- ‘best’:自动选择合适的地方
- ‘upper right’:右上方
- ‘upper left’:左上方
- ‘lower left’:左下方
- ‘lower right’:右下方
- ‘right’:右侧
- ‘center left’:左侧居中
- ‘center right’:右侧居中
- ‘lower center’:底部居中
- ‘upper center’:顶部居中
- ‘center’:居中
对于多条折线图来说,想要改变某条折线的属性的方式和单条折线的方式一致,参考上面的方法即可。
柱状图绘制
柱状图(bar chart),是一种以长方形的长度为变量的表达图形的统计报告图,由一系列高度不等的纵向条纹表示数据分布的情况,用来比较两个或以上的价值(不同时间或者不同条件),只有一个变量,通常利用于较小的数据集分析。 柱状图亦可横向排列,或用多维方式表达。
这里绘制柱状图使用的数据为 fandango_scores.csv,这是2014-2015年间部分电影在各大评分网站上的评分数据。
首先来加载数据
film_data = pd.read_csv('./data/fandango_scores.csv')
# 选取指定的列来处理
some_film_data = film_data[['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars']]
接下来来绘制柱状图,在绘制柱状图的过程中得首先准备好如下一些数据:
- 柱高:每个柱的取值高度
- 柱偏移:每个柱之间相距的距离
- 柱宽:每个柱的宽度
获取到了这些数据之后便可以可以创建一个柱状图对象。创建的柱状图包括:垂直的和水平的两种,分别对应与 bar 和 barh。
创建垂直柱状图:
import numpy as np
# 所需要显示的数据列,也就是每一个柱
cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars']
# 获取数据第一行中指定列的数值来做为柱高
bar_heights = some_film_data.loc[0, cols].values
# print(bar_heights)
# 柱偏移
bar_positions = np.arange(5) + 1
# print(bar_positions)
# 创建一个画图对象(可以创建多个),plt用来控制整体的图像属性,ax负责图像本身的绘制
fig,ax = plt.subplots()
# 创建柱状图,传入参数为 柱偏移,柱高, 柱宽
ax.bar(bar_positions, bar_heights, 0.3)
# 设置x轴标签位置
tick_positions = range(1,6)
ax.set_xticks(tick_positions)
# 设置x轴标签
ax.set_xticklabels(cols, rotation=45)
# 设置该图像的基本信息
ax.set_xlabel('Rating Source')
ax.set_ylabel('Average Rating')
ax.set_title('Average User Rating For Avengers: Age of Ultron (2015)')
# 设置整个图像的大小
fig.set_size_inches(8,5)
# 显示图像
plt.show()
显示结果:
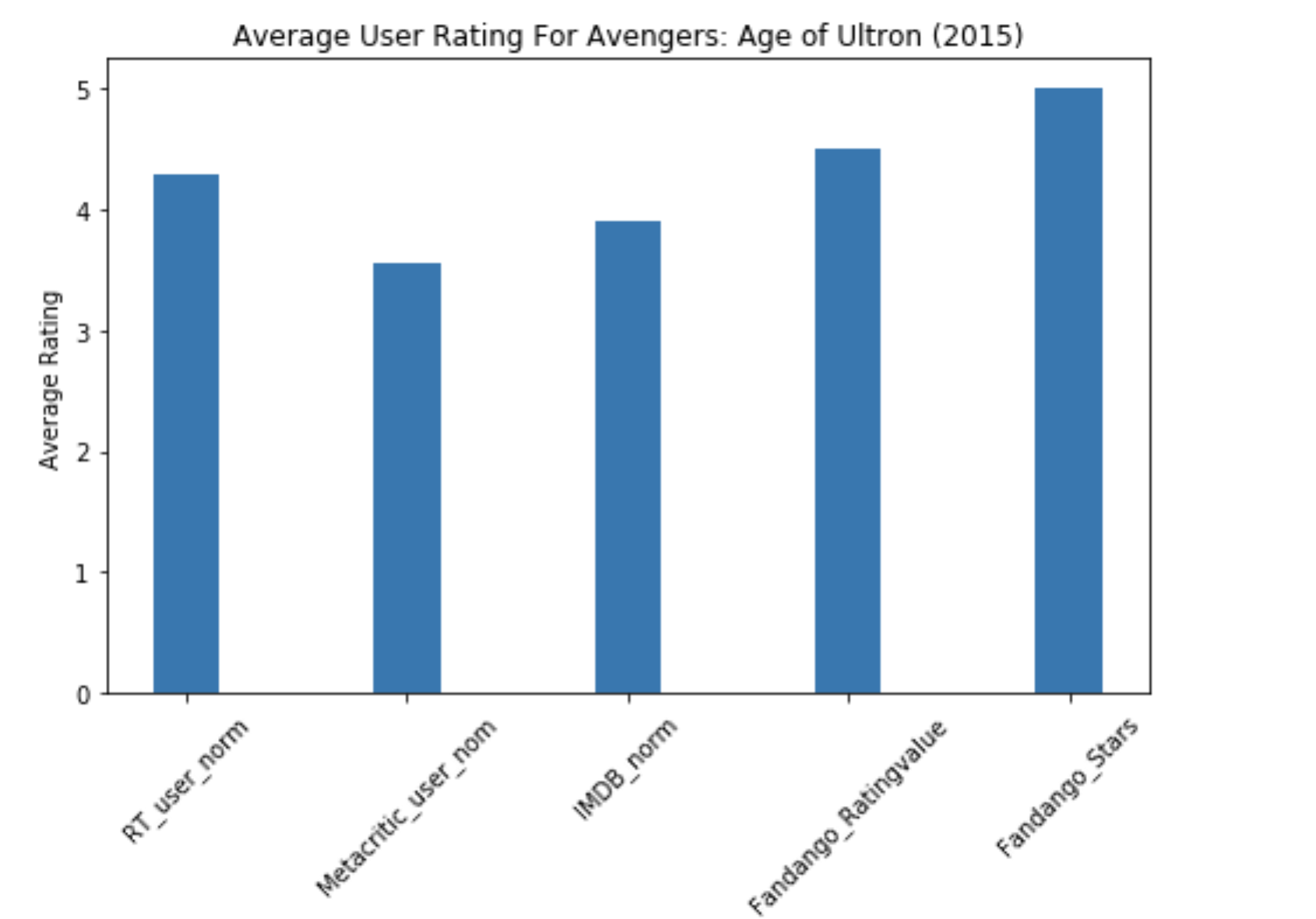
创建水平柱状图:
# 柱的宽度(也就是高度)
bar_widths = some_film_data.loc[0, cols].values
# 柱偏移
bar_positions = np.arange(5) + 1
# 创建对应的图像显示对象
fig, ax = plt.subplots()
# 创建一个水平的柱状图
ax.barh(bar_positions, bar_widths, 0.5)
# 设置y轴标签位置
tick_positions = range(1,6)
ax.set_yticks(tick_positions)
# 设置y轴标签
ax.set_yticklabels(cols)
# 设置该图像的基本信息
ax.set_ylabel('Rating Source')
ax.set_xlabel('Average Rating')
ax.set_title('Average User Rating For Avengers: Age of Ultron (2015)')
# 设置整个图像的大小
fig.set_size_inches(8,5)
# 显示图像
plt.show()
显示结果:
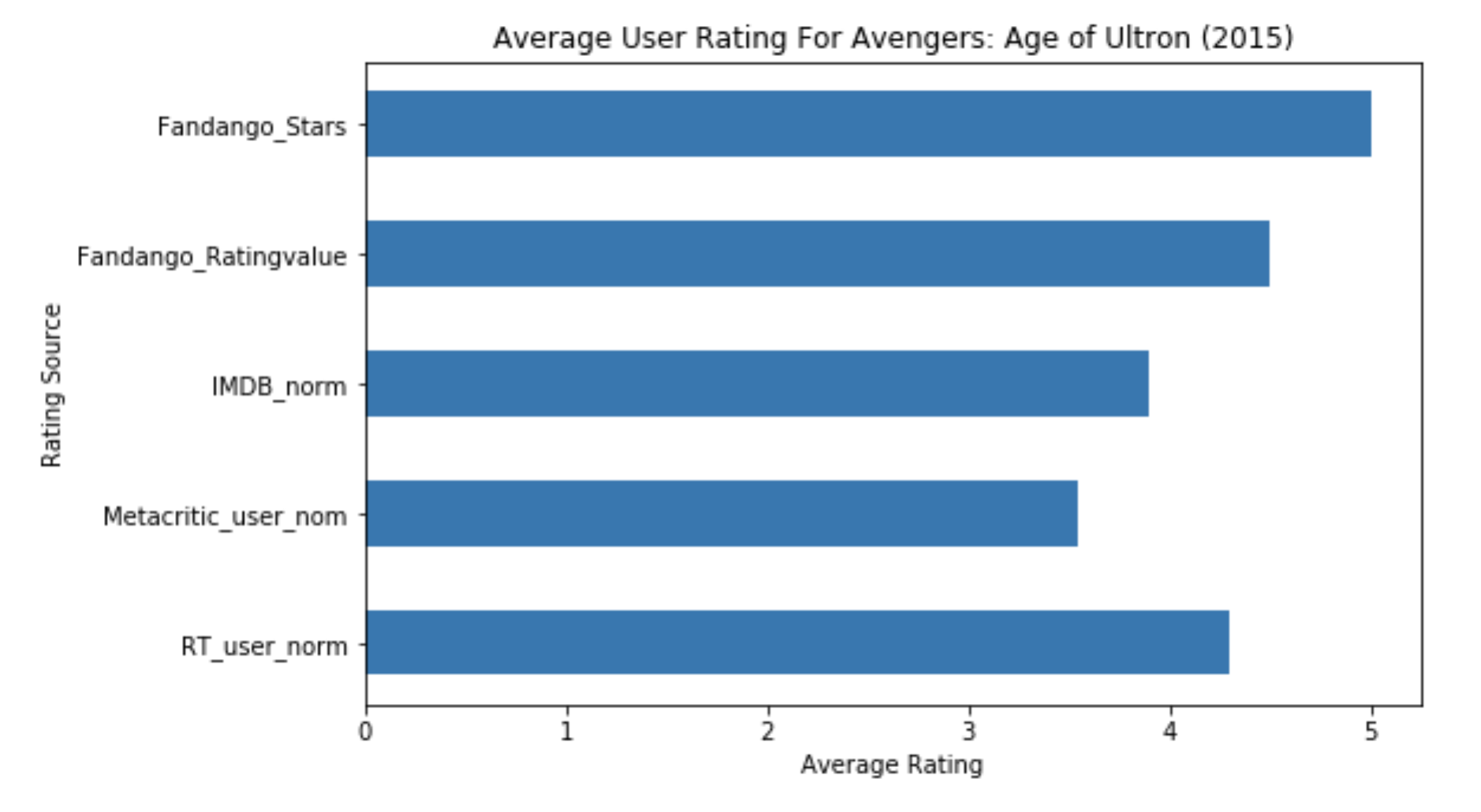
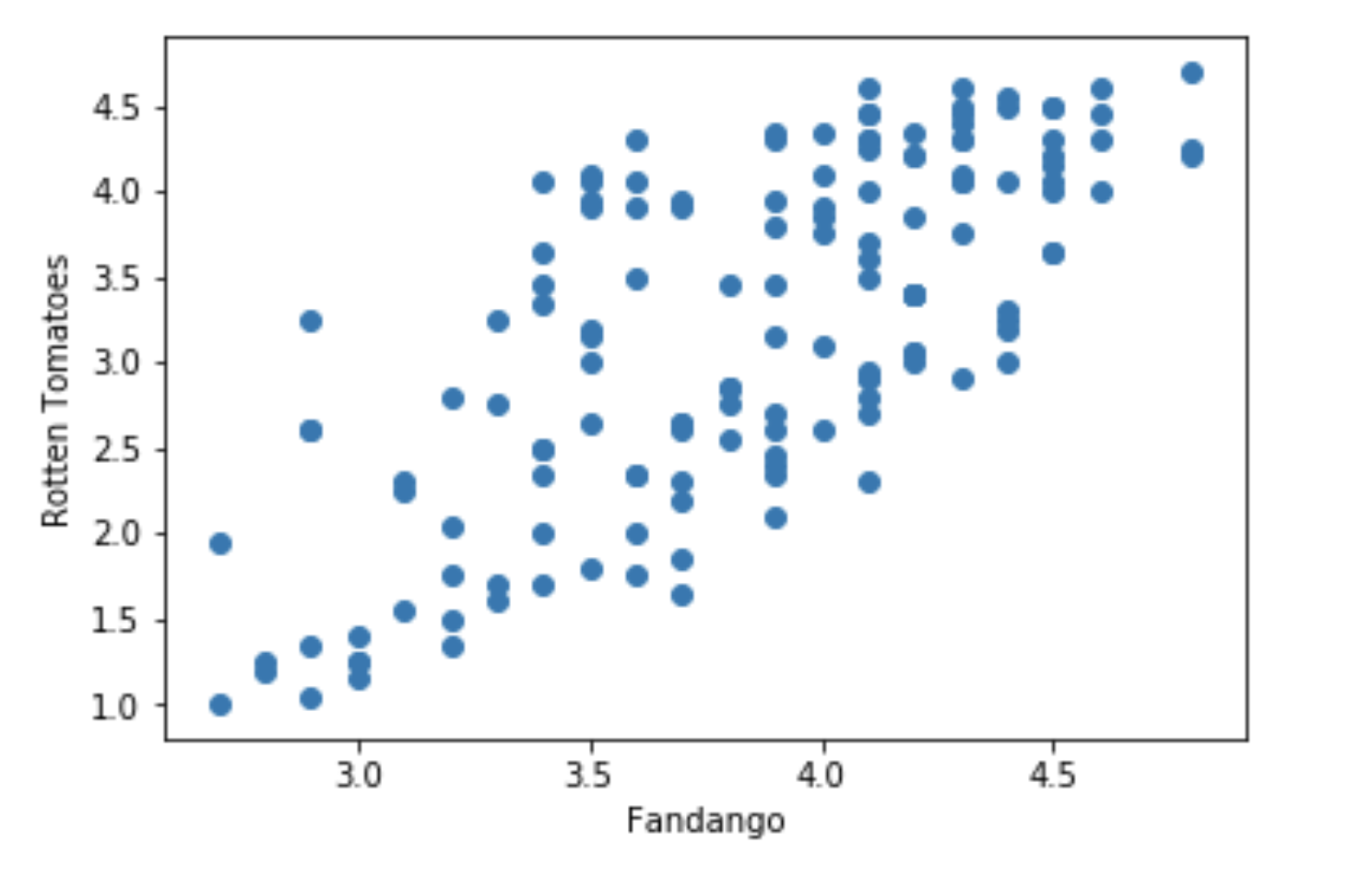
散点图绘制
散点图是指在回归分析中,数据点在直角坐标系平面上的分布图,散点图表示因变量随自变量而变化的大致趋势,据此可以选择合适的函数对数据点进行拟合。 用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。 散点图将序列显示为一组点。 值由点在图表中的位置表示。
跟绘制柱状图调用 bar类似,散点图也是直接调用 scatter函数,并传入对应的 x 和 y 数据就可以了。
fig, ax = plt.subplots()
# 创建散点图对象并传入对应x,y数据
ax.scatter(some_film_data['Fandango_Ratingvalue'],
some_film_data['RT_user_norm'])
# 指定图像标签
ax.set_xlabel('Fandango')
ax.set_ylabel('Rotten Tomatoes')
# 显示图像
plt.show()
显示结果:
箱形图绘制
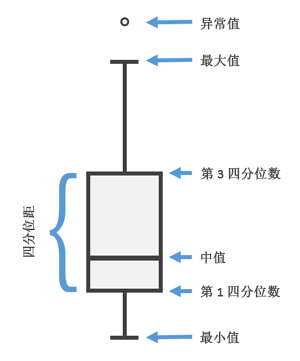
箱形图,又称为盒须图、盒式图、盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因型状如箱子而得名。此图中之盒子之外,也常会有线条在上下四分位数之外延伸出去,像是胡须,因此也称为盒须图。离群值会有时会画成是个别的点。箱型图是无母数的,他显示样品的特性,对于母体分布并无任何假设。
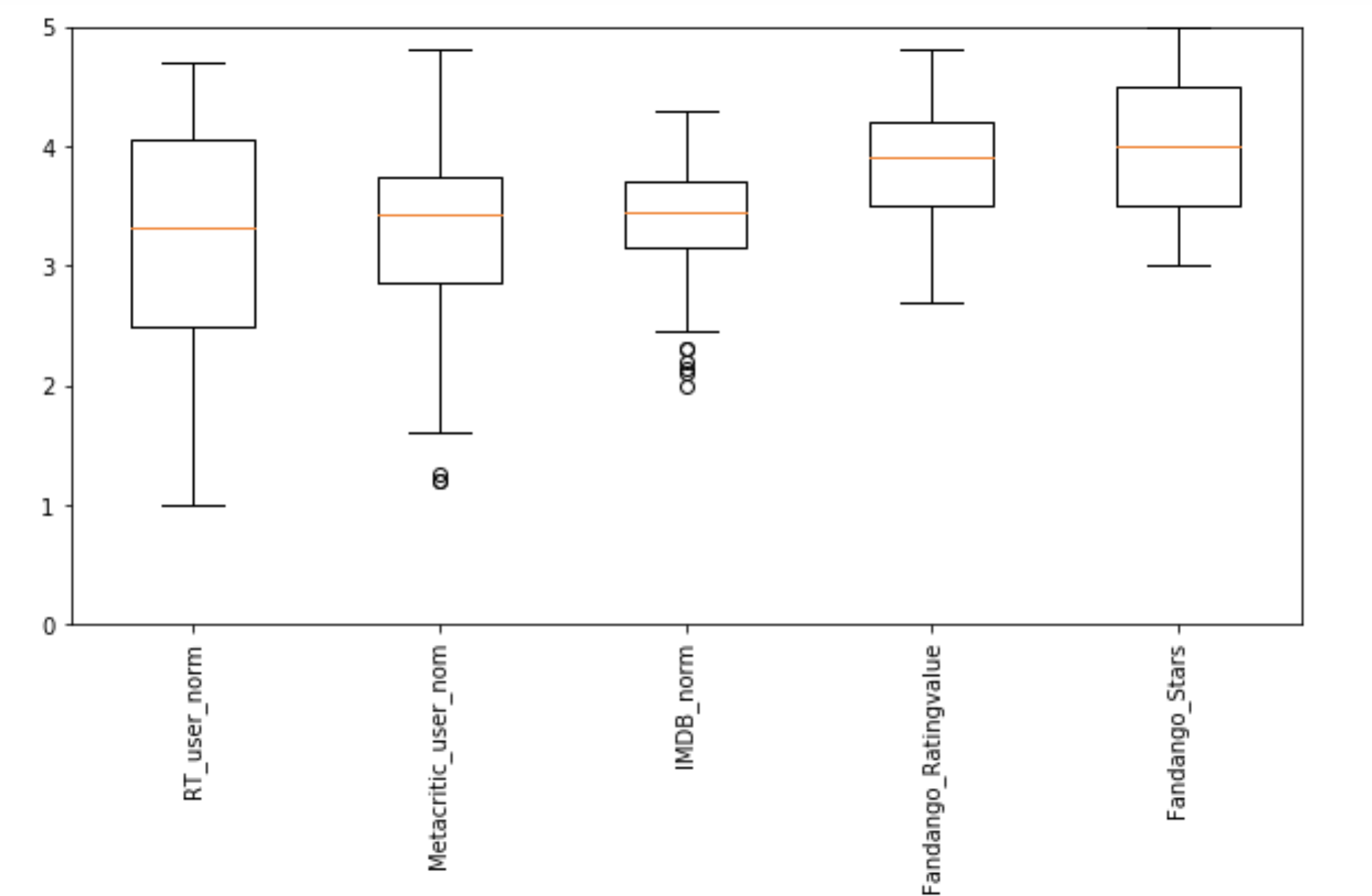
使用 matplotlib 来绘制 箱形图是比较简单的,只需要使用 boxplot 函数即可。
# 箱型图绘制
fig, ax = plt.subplots()
# 创建一个对应的箱型图对象
# print(some_film_data[cols].values)
ax.boxplot(some_film_data[cols].values)
# 设置x轴的标签和角度
ax.set_xticklabels(cols, rotation=90)
# 设置y轴的范围
ax.set_ylim(0,5)
# 设置图像大小
fig.set_size_inches(10,5)
# 显示图像
plt.show()
显示结果:
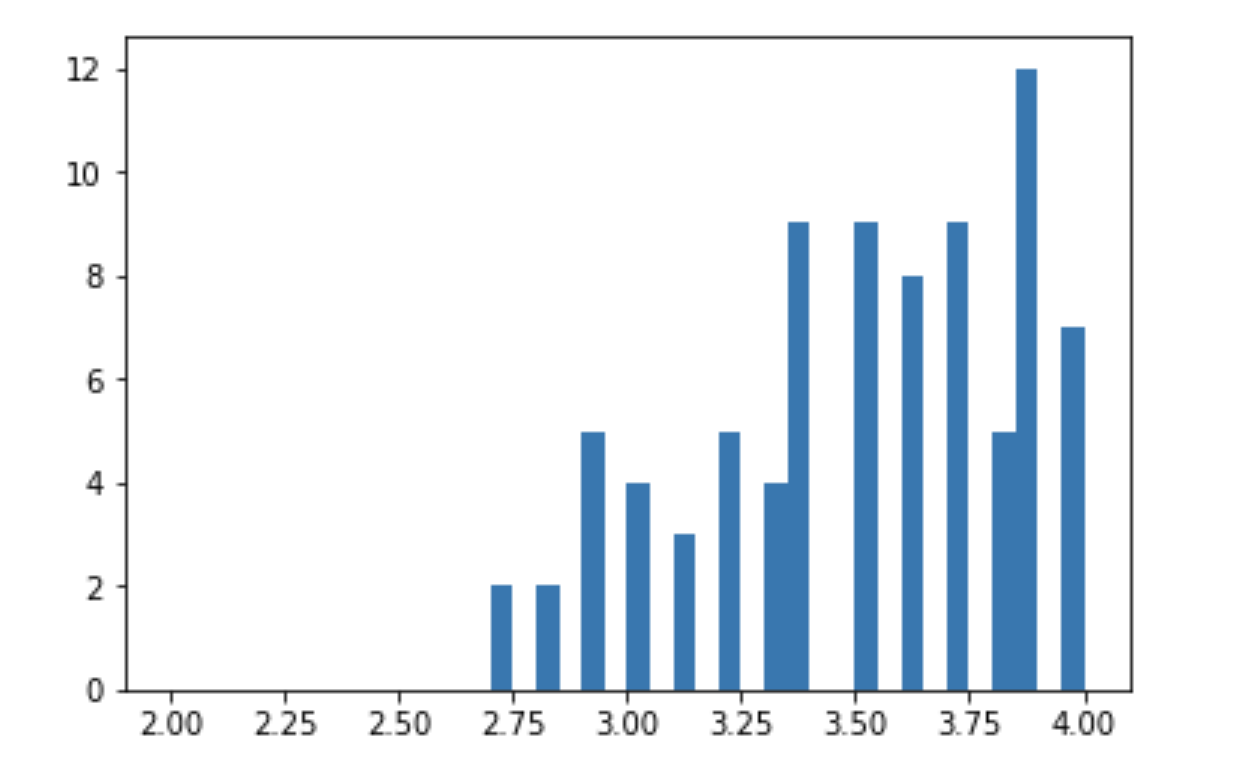
直方图绘制
直方图(Histogram)又称质量分布图。 是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。 一般用横轴表示数据类型,纵轴表示分布情况。 直方图是数值数据分布的精确图形表示。
使用 matplotlib 中的 hist 方法来绘制直方图
fig,ax = plt.subplots()
# 绘制直方图对象,传入数据以及参数
ax.hist(some_film_data['Fandango_Ratingvalue'], bins=40, range=(2,4))
# 显示图像
plt.show()
其中的参数都是在传入的数据的基础上的:
- bins:数据分组数
- range:数据显示范围
显示结果:
还可以结合子图来显示多个直方图:
fig = plt.figure(figsize=(10,6))
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
ax1.hist(some_film_data['Fandango_Ratingvalue'], bins=20, range=(0, 5))
ax1.set_title('Distribution of Fandango Ratings')
ax1.set_ylim(0, 50)
ax2.hist(some_film_data['RT_user_norm'], 20, range=(0, 5))
ax2.set_title('Distribution of Rotten Tomatoes Ratings')
ax2.set_ylim(0, 50)
ax3.hist(some_film_data['Metacritic_user_nom'], 20, range=(0, 5))
ax3.set_title('Distribution of Metacritic Ratings')
ax3.set_ylim(0, 50)
ax4.hist(some_film_data['IMDB_norm'], 20, range=(0, 5))
ax4.set_title('Distribution of IMDB Ratings')
ax4.set_ylim(0, 50)
plt.show()
显示结果:
总结
以上的一些图形只是我们在今后的数据分析中经常会使用到的一些。其实在工作或学习中遇到需要显示的图形的时候可以去官网查看对应的图形的案例,替换数据,照着修改即可。记住,这些都只是工具,是为了我们更好的分析数据而提供的,我们会用即可。
查看作者信息
