Python3 爬虫(二十一):Scrapy 实战项目四:新浪网全站资讯
新浪全站咨询爬取
新浪是中国门户网站公司,一家服务中国大陆及全球华人社群的中文网络内容服务提供商。新浪与腾讯、搜狐和网易并称中国四大门户网站。新浪在全球范围内注册用户超过6亿,日浏览量超过12亿次。本次我们要爬取的是新浪网全站各分类下的资讯内容。
一、数据分析
1.爬取任务
要爬取的网站界面是:http://news.sina.com.cn/guide/。我们要将新闻资讯类下除了地方站之外的所有的分类资讯中对应的文章都获取到。
要获取的是 大分类–》小分类–》文章–》文章内容这么一个大概的爬取流程。并且,为了演示,只获取某一小分类中第一页的相关数据即可。
也就是说,先获取分类界面中所有的一级分类以及所有的二级分类

之后得进入到指定的二级目录下的网页中,在这个网页中得获取所有的文章链接

之后进入到相应的文章链接中去,获取对应的文章的标题和内容信息
到这里,所有的爬取任务结束。
2.数据分析
根据爬取任务我们可以明确所需要爬取的数据包括:
- 一级标题名称
- 一级标题链接
- 二级标题名称
- 二级标题链接
- 文章链接
- 文章标题
- 文章内容
3.数据获取
接下来分别从网页中获取相应的数据,这里是使用 xpath来从网页中解析数据。
分类界面数据获取
首先分析对应的网页源码
<div class="section" id="tab01">
<h2 class="tit01" style="padding-top:5px;">新闻<code class="s_dot">·</code>资讯</h2>
<div class="clearfix" data-sudaclick="newsnav">
<h3 class="tit02" style="border-color:#1e3f8c;"><a href="http://news.sina.com.cn/">新闻</a></h3>
<ul class="list01">
<li><a href="http://news.sina.com.cn/china/">国内</a></li>
...
</ul>
</div>
...
</div>
可以看到,在 tab01 之内的 h3 是每一个一级标题,而在 tab01 之内的 ul/li 是每一个二级标题的内容。那么对应的网站分类页面就可以获取到所有的一级分类名称链接以及所有的二级分类名称以及链接。
那么相应内容的 xpath 提取规则为:
- 一级分类名称://div[@id=”tab01”]//h3/a/text()
- 一级分类链接://div[@id=”tab01”]//h3/a/@href
- 二级分类名称://div[@id=”tab01”]/div/ul/li/a/text()
- 二级分类链接://div[@id=”tab01”]/div/ul/li/a/@href
二级分类界面数据获取
首先分析对应的网页源码
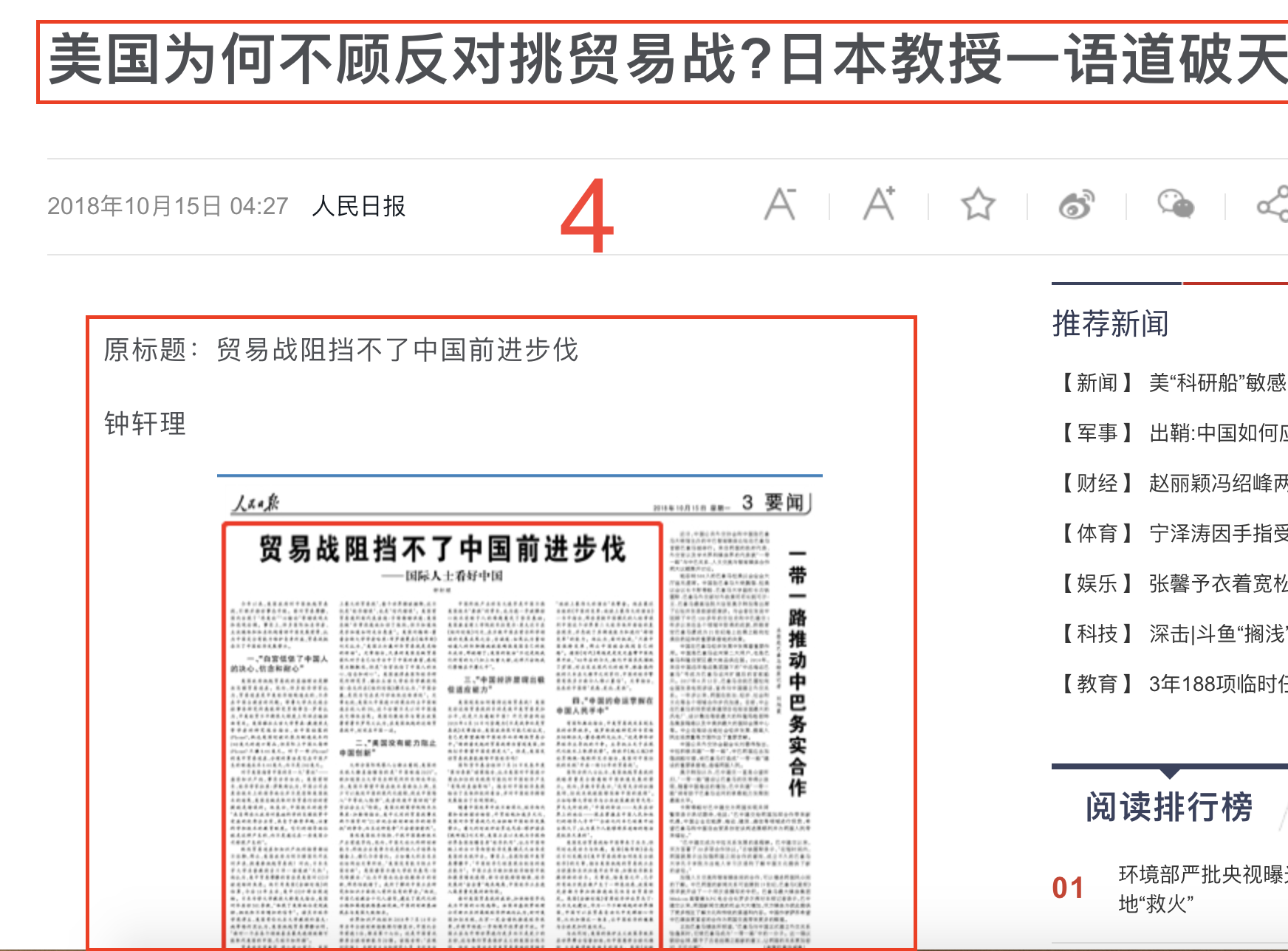
<a href="https://news.sina.com.cn/c/2018-10-14/doc-ihmhafir5592923.shtml" target="_blank">为了“捞出”武长顺 她送出去60张银行卡</a>
发现,每一个文章的链接都是上面的那种格式。因此,我们可以将网页上所有的 a链接提取出来,之后在判断其是否是文章链接即可。
而只要是文章链接的话,那么其肯定是由二级分类的网址开头并且以 .shtml结尾,通过判断每一个链接的 url 格式便可以将当前网页中所有的文章链接获取到。
文章界面数据获取
首先分析对应的网页源码
<h1 class="main-title">美国为何不顾反对挑贸易战?日本教授一语道破天机</h1>
...
<p> 美国政府挑起贸易战的直接理由是解决巨额贸易逆差。然而,许多经济学家认为,贸易逆差是中美经济结构造成的,不存在中国占便宜的问题。耶鲁大学杰克逊全球事务研究所高级研究员斯蒂芬·罗奇认为,中美经贸不平衡很大程度上同供应链扭曲有关。美国锡拉丘兹大学贾森·戴德里克等学者的研究报告指出,由中国组装的iPhone7,抵达美国时被记录为制造成本约240美元的进口商品,但实际上中国从每部iPhone7只赚8.46美元。对于一部iPhone7的美中贸易逆差,合理的算法是它在中国产生的制造成本8.46美元,而不是240美元。</p>
...
可以看到,文章的标题都是 h1 标签,而文章的内容基本都在 p 标签内(注意在p标签内的还有其他数据,这个可以在后期进行处理删除掉)
那么相应内容的 xpath 提取规则为:
- 文章标题://h1/text()
- 文章内容://p/text()
二、爬虫设计
1.数据 items 设计
那么相应的所需保存到对应 item 的数据也就明确了:
- 文章一级标题名称:type_1
- 文章二级标题名称:type_2
- 文章二级链接:url
- 文章存储地址:path
- 文章名称:name
- 文章内容:content
2.spider 类设计
这次的爬取任务是获取全站的资讯信息,因此需要使用 Scrapy框架来进行,这样会将各个功能块划分开来,分别处理。
一般来说,爬去整站数据都是使用 CrawlSpider来进行的,但是这是个简单的演示示例,因此我们只爬取每个二级分类的额第一页的数据,而不是整站爬取,因此我们使用 Spider就可以满足要求了。
根据爬取任务的不同爬虫的处理任务也就可以分为:
- 处理分类界面的 parse(self, response)
- 处理二级分类界面的 parse_type_2(self, response)
- 处理文章界面的 parse_type_2
3.中间件设计
中间件我们只让其实现使用随机的 User-Agent请求即可。
4.管道设计
管道处理就是将 item 数据中的 item[‘content’] 内容保存到本地对应的 item[‘path’] 路径中去,并且以 item[‘name’] 来命名
三、编程
1.创建项目
scrapy startproject sinaSpider
cd sinaSpider/sinaSpider/spiders
scrapy genspider sina sian.com.cn
2.items.py
import scrapy
class SinaspiderItem(scrapy.Item):
# 文章的主分类
type_1 = scrapy.Field()
# 文章的二级分类
type_2 = scrapy.Field()
# 文章的标题
name = scrapy.Field()
# 文章内容
content = scrapy.Field()
# 文章二级分类的url
url = scrapy.Field()
# 文章的存储路径
path = scrapy.Field()
3.sina.py
# -*- coding: utf-8 -*-
import scrapy
import os
from sinaSpider.items import SinaspiderItem
class SinaSpider(scrapy.Spider):
name = 'sina'
allowed_domains = ['sina.com.cn']
start_urls = ['http://news.sina.com.cn/guide/']
def parse(self, response):
"""
解析初始页面
"""
items = []
# 现将一级标题解析出来
type_1_urls = response.xpath('//div[@id="tab01"]//h3/a/@href').extract()
type_1_names = response.xpath('//div[@id="tab01"]//h3/a/text()').extract()
# 接下来解析对应的二级标题
type_2_urls = response.xpath('//div[@id="tab01"]/div/ul/li/a/@href').extract()
type_2_names = response.xpath('//div[@id="tab01"]/div/ul/li/a/text()').extract()
for i in range(0, len(type_1_names)):
# 根据第一级标题来创建文件夹
type_1_file_name = './data/'+type_1_names[i]
if not os.path.exists(type_1_file_name):
os.makedirs(type_1_file_name)
# 开始处理所有的二级分类
for j in range(0, len(type_2_names)):
item = SinaspiderItem()
# 保存一级分类
item['type_1'] = type_1_names[i]
# 判断二级分类是否是以一级分类开头的
is_belong = type_2_urls[j].startswith(type_1_urls[i])
# 如果是符合的子类,则可以继续处理
if is_belong:
# 根据二级标题来创建文件夹
type_2_file_name = type_1_file_name+'/'+type_2_names[j]
if not os.path.exists(type_2_file_name):
os.makedirs(type_2_file_name)
# 保存item相关信息
item['type_2'] = type_2_names[j]
item['path'] = type_2_file_name
item['url'] = type_2_urls[j]
items.append(item)
# 去请求对应的二级标题的界面
for item in items:
yield scrapy.Request(url = item['url'], callback=self.parse_type_2, meta={'meta_1':item})
def parse_type_2(self, response):
"""
解析小标题页面
"""
# 获取对应的meta数据
item = response.meta['meta_1']
# 取出二级界面中所有的链接
urls = response.xpath('//a/@href').extract()
for i in range(0, len(urls)):
# 判断哪些链接是属于文章的链接
is_belong = urls[i].startswith(item['url']) and urls[i].endswith('.shtml')
# 是文章的话就继续去处理
if is_belong:
yield scrapy.Request(url = urls[i], callback=self.parse_content, meta={'item':item})
def parse_content(self, response):
"""
解析文章界面
"""
# 获取对应的meta数据
item = response.meta['item']
# 解析出文章的标题
item['name'] = response.xpath('//h1/text()')[0].extract()
# 解析出文章的内容
item['content'] = ''.join(response.xpath('//p/text()').extract())
yield item
3.pipelines.py
class SinaspiderPipeline(object):
def __init__(self):
"""
初始化操作
"""
pass
def process_item(self, item, spider):
"""
将数据写入到文件中去
"""
with open(item['path']+'/'+item['name']+'.txt', 'w', encoding='utf-8') as file:
file.write(item['content'])
return item
def close_spider(self, spider):
"""
执行结束后操作
"""
pass
4.middlewares.py
import random
import base64
# 从设置文件中导入所需的数据
from sinaSpider.settings import USER_AGENTS
class RandomUserAgentMiddleware(object):
"""
随机更换请求中的user-agent
"""
def process_request(self, request, spider):
"""
将请求头中的默认参数user-agent设置为自己从ua池中随机挑选的
"""
user_agent = random.choice(USER_AGENTS)
# print(user_agent)
request.headers.setdefault('User-Agent', user_agent)
5.settings.py
# -*- coding: utf-8 -*-
BOT_NAME = 'sinaSpider'
SPIDER_MODULES = ['sinaSpider.spiders']
NEWSPIDER_MODULE = 'sinaSpider.spiders'
DOWNLOAD_DELAY = 2.5
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}
DOWNLOADER_MIDDLEWARES = {
'sinaSpider.middlewares.RandomUserAgentMiddleware': 100,
}
# 随机user- agent列表
USER_AGENTS = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11'
]
ITEM_PIPELINES = {
'sinaSpider.pipelines.SinaspiderPipeline': 300,
}
6.执行项目
scrapy crawl sina
7.查看结果
查看作者信息
