Python3 爬虫(二十):Scrapy 实战项目三:豆瓣电影 Top 250
豆瓣电影 Top 250
豆瓣电影 Top 250,是豆瓣用户每天都在对“看过”的电影进行“很差”到“力荐”的评价,豆瓣根据每部影片看过的人数以及该影片所得的评价等综合数据,通过算法分析产生豆瓣电影 Top 250。
我们这一次要使用爬虫来将豆瓣电影 Top 250中的所有电影的信息保存到 MongoDB数据库当中。
项目分析
本次的项目是从指定的网页中获取到对应数据之后将其存放到 MongoDB 数据库中去,并且还得使用到相应的反反爬虫机制。因此,主要的任务也就是:
- 明确所要获取的数据
- 使用反反爬虫来获取数据
- 将数据保存到 MongoDB 数据库当中
接下来分别进行相应的任务
一、数据分析
豆瓣电影 Top 250,从指定的网页中需要爬取的信息包括:
- 电影名称
- 电影评分
- 电影简介
所对应的网页源码为:
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.6</span>
<span property="v:best" content="10.0"></span>
<span>1166728人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
根据对应的网页源码可以获取到所需数据对应的 xpath 解析规则
- 电影名称://span[@class=”title”][1]/text()
- 电影评分://span[@class=”rating_num”]/text()
- 电影简介://span[@class=”inq”]/text()
二、反反爬虫机制
为了保证爬虫能够正常的工作,必要的反反爬虫策略是必须要使用的。
在本项目中使用到了两种反反爬虫机制:随机User-Agent 以及 代理池
1.随机User-Agent
为了保证爬虫在运行的过程中不会遭到屏蔽,因此每一次请求的时候都应该更换一下请求中对应的 User-Agent,在这里,推荐大家去访问常用 User-Agent 整理,来获取相应对的不同的 User-Agent。
在项目中,这些对应的 User-Agent 是放在 settings.py 设置文件中,以列表的形式保存,当需要时直接在文件中导入即可。在使用 random 中的 choice方法从中随机获取一个即可。
2.代理池
目前常见的反爬虫的处理机制是封 IP ,因此,在爬虫允许的时候是一定不能使用自己本机的 IP 的,这里推荐几个常用的寻找免费代理的网站,但是为了爬虫程序的高效性,一般来说建议去购买一些专属的代理。
- https://www.kuaidaili.com/free/
- http://www.xicidaili.com/
- https://proxy.mimvp.com/free.php
- http://www.data5u.com/free/gwgn/index.shtml
- http://31f.cn/
- http://lab.crossincode.com/proxy/
上面的这些是免费的代理,一般来说测试使用即可,但基本上使用不了。为了高效的进行爬虫允许,我们都是购买一些收费的私密代理。而这些代理一般来说都是需要使用账户名和密码来进行授权的。
而在请求中使用需要授权的代理 IP 时,需要先将对应的账户名和密码进行 Base64 加密处理。之后在添加到代理服务器请求的信令 Proxy-Authorization 中去。
# 对账号和密码进行加密处理
base64_user_pwd = base64.b64encode('账号:密码'.encode('utf-8')).decode('utf-8')
# 添加到对应的代理服务器请求的信令格式中,注意 Base64后面有个空格
request.headers['Proxy-Authorization'] = 'Basic '+base64_user_pwd
在项目中,这些对应的代理池是放在 settings.py 设置文件中,以列表的形式保存,当需要时直接在文件中导入即可。在使用 random 中的 choice方法从中随机获取一个即可。
三、MongoDB 数据存储
MongoDB 在 Python 中的使用方式在之前已经讲过了,请查看 Python3 MongoDB 数据库连接
这里主要是将我在调试代码的过程中所遇到的一个问题:
pymongo.errors.InvalidURI: Username and password must be escaped according to RFC 3986, use urllib.parse.quote_plus()
出现该问题是因为在进行远程的 MongoDB 数据库访问时,所对应的账户名和密码需要进行加密处理,并且也给你指定了所需要用到的加密方法,直接调用即可。
user_name = urllib.parse.quote_plus('user_name')
password = urllib.parse.quote_plus('password')
四、项目代码
1.创建项目
scrapy startproject doubanSpider
doubanSpider/doubanSpider/spiders/
scrapy genspider douban douban.com
2.编写 items.py 文件
import scrapy
class DoubanspiderItem(scrapy.Item):
# 电影名称
name = scrapy.Field()
# 电影评分
score = scrapy.Field()
# 电影简介
info = scrapy.Field()
3.编写 douban.py 爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from doubanSpider.items import DoubanspiderItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['douban.com']
url = 'https://movie.douban.com/top250?start='
offset = 0
start_urls = [url+str(offset)]
def parse(self, response):
movies = response.xpath('//div[@class="item"]')
for movie in movies:
item = DoubanspiderItem()
# 解析网页响应
item['name'] = movie.xpath('.//span[@class="title"][1]/text()').extract()[0]
item['score'] = movie.xpath('.//span[@class="rating_num"]/text()').extract()[0]
item['info'] = movie.xpath('.//span[@class="inq"]/text()').extract()[0]
yield item
# 继续发送请求
if self.offset < 225:
self.offset += 25
yield scrapy.Request(self.url+str(self.offset), callback=self.parse)
4.编写配置文件 settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for doubanSpider project
BOT_NAME = 'doubanSpider'
SPIDER_MODULES = ['doubanSpider.spiders']
NEWSPIDER_MODULE = 'doubanSpider.spiders'
COOKIES_ENABLED = False
# 优先级随机user-agent的优先级高于随机代理
DOWNLOADER_MIDDLEWARES = {
'doubanSpider.middlewares.RandomUserAgentMiddleware': 100,
'doubanSpider.middlewares.RandomProxiesMiddleware': 200,
}
# 随机user- agent列表
USER_AGENTS = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11'
]
# HTTP随机代理ip地址
PROXIES =[
{'type':'HTTP', 'ip_port':'180.104.62.149:9000','user_pwd':''},
{'type':'HTTP', 'ip_port':'115.159.221.219:8118', 'user_pwd':''},
{'type':'HTTP', 'ip_port':'218.90.174.37:35577', 'user_pwd':''},
{'type':'HTTP', 'ip_port':'121.232.148.147:9000', 'user_pwd':''},
{'type':'HTTP', 'ip_port':'59.108.125.241:8080', 'user_pwd':''},
{'type':'HTTP', 'ip_port':'183.230.177.118:8060', 'user_pwd':''}
]
# MONGODB配置信息
MONGODB_HOST = '127.0.0.1'
MONGODB_PORT = '27017'
MONGODB_DB_NAME = 'douban_movie'
MONGODB_COLL_NAME = 'top_250'
ITEM_PIPELINES = {
'doubanSpider.pipelines.DoubanspiderPipeline': 300,
}
5.编写 下载中间件 middlewares.py
import random
import base64
# 从设置文件中导入所需的数据
from doubanSpider.settings import USER_AGENTS
from doubanSpider.settings import PROXIES
class RandomUserAgentMiddleware(object):
"""
随机更换请求中的user-agent
"""
def process_request(self, request, spider):
"""
将请求头中的默认参数user-agent设置为自己从ua池中随机挑选的
"""
user_agent = random.choice(USER_AGENTS)
# print(user_agent)
request.headers.setdefault('User-Agent', user_agent)
class RandomProxiesMiddleware(object):
"""
随机使用ip代理来进行访问
"""
def process_request(self, request, spider):
"""
在请求中使用代理来进行访问
"""
proxy = random.choice(PROXIES)
# print(proxy)
# 接下来需要对进行验证的ip进行处理
if proxy['user_pwd'] is not None:
# 有代理验证,需要进行base64对账号和密码进行加密
base64_user_pwd = base64.b64encode(proxy['user_pwd'].encode('utf-8')).decode('utf-8')
# 添加到对应的代理服务器请求的信令格式中,注意 Base64后面有个空格
request.headers['Proxy-Authorization'] = 'Basic '+base64_user_pwd
# 进行代理ip的设置
request.meta['proxy'] = proxy['type']+'://'+proxy['ip_port']
6.编写管道处理文件 pipelines.py
import pymongo
import urllib
from pymongo import MongoClient
# 从设置文件中导入所需的mongodb配置文件
from doubanSpider.settings import MONGODB_HOST
from doubanSpider.settings import MONGODB_PORT
from doubanSpider.settings import MONGODB_DB_NAME
from doubanSpider.settings import MONGODB_COLL_NAME
class DoubanspiderPipeline(object):
def __init__(self):
"""
初始化数据库的连接
"""
# 创建数据库连接
# 出现问题:pymongo.errors.InvalidURI: Username and password must be escaped according to RFC 3986, use urllib.parse.quote_plus()
user_name = urllib.parse.quote_plus('user_name')
password = urllib.parse.quote_plus('password')
url = 'mongodb://%s:%s@%s:%s/?authSource=admin&authMechanism=MONGODB-CR'%(user_name,password, MONGODB_HOST, MONGODB_PORT)
self.client = MongoClient(url)
# 指定数据库
db = self.client[MONGODB_DB_NAME]
# 指定集合
self.collection = db[MONGODB_COLL_NAME]
def process_item(self, item, spider):
"""
将数据保存到数据库之中
"""
# item数据为类字典类型,首先得将其转换为字典类型
data = dict(item)
self.collection.insert(data)
return item
def close_spider(self, spider):
"""
爬虫运行结束之后关闭数据库
"""
self.client.close()
7.启动项目
scrapy crawl douban
8.运行结果
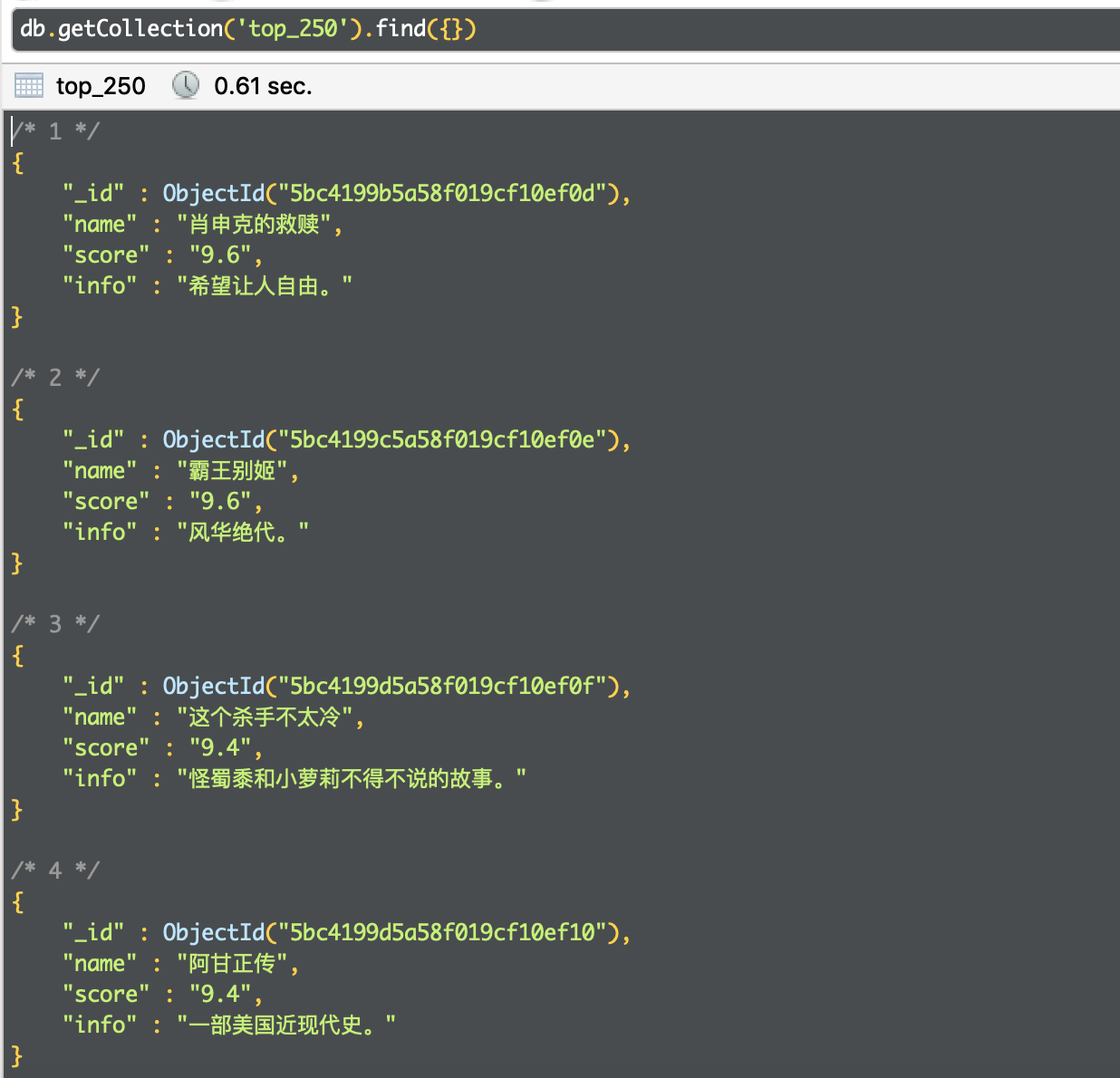
通过 Mongo Robo 来查看 MongoDB 数据库中已经保存了爬取的数据
查看作者信息
