Python3 爬虫(十六):Scrapy 实战项目二:东莞阳光网
Scrapy 实战项目二:东莞阳光网
东莞阳光网是东莞市的一个本地信息平台,我们本次要爬取的内容是东莞阳光网下的一个阳光热线问政平台,该平台是对全市的一些市民反映的问题进行集中处理的地方。
我们本次所要爬取的便是该平台下的所有问题内容。
一、网页分析
明确了要爬取的内容之后就可以来分析下对应的网页的结构。
首先是主要的阳光热线问政平台的网页
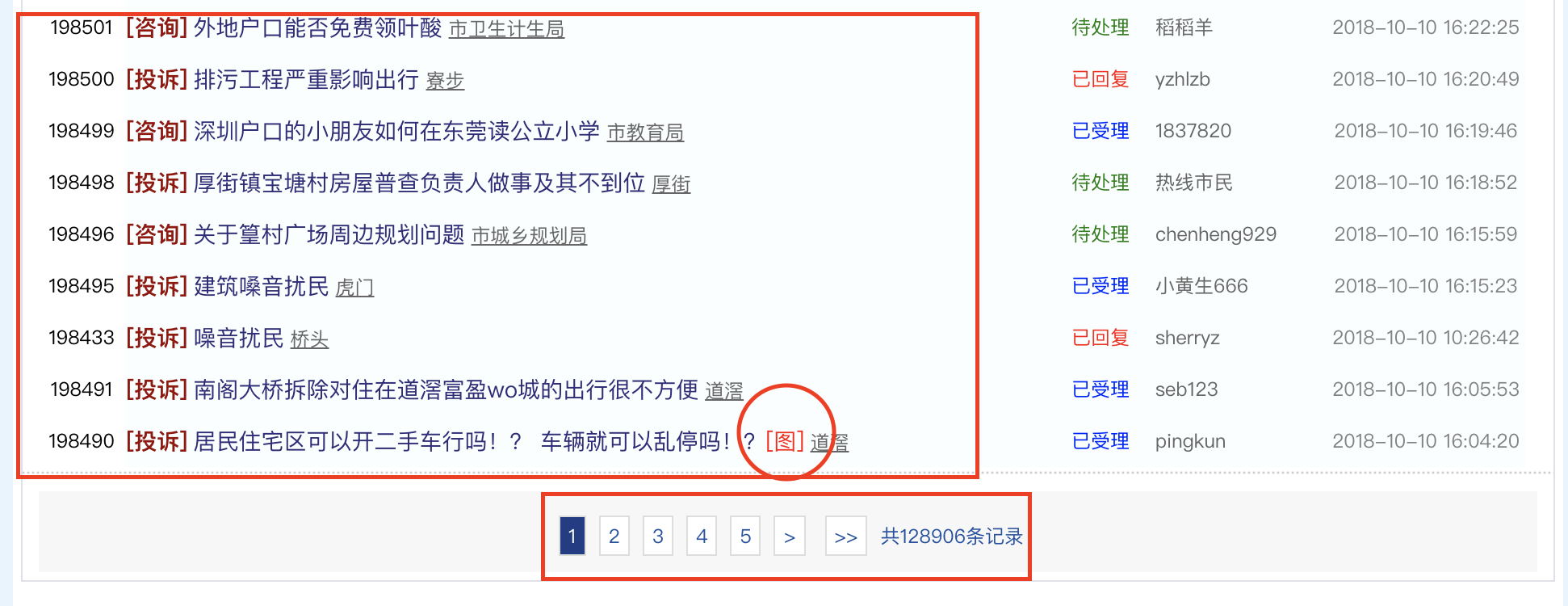
可以看到,该网页主要是由问题列表和不同网页的跳转链接组成的。注意,有些问题是包含图片的,这些包含图片的问题之后处理的时候得重点小心。
首先先来看下不同网页之间的跳转链接,查看其源码
<a href="http://wz.sun0769.com/index.php/question/report?page=30">2</a>
<a href="http://wz.sun0769.com/index.php/question/report?page=60">3</a>
<a href="http://wz.sun0769.com/index.php/question/report?page=90">4</a>
可以看到不同网页的链接只是 page 的值再发生变化,因此便可以得到对应于网页链接的正则表达式
/question/report\?page=\d+
之后在看下页面中的问题列表的链接
<a href="http://wz.sun0769.com/html/question/201810/388510.shtml" title="排污工程严重影响出行" target="_blank" class="news14">排污工程严重影响出行</a>
<a href="http://wz.sun0769.com/html/question/201810/388517.shtml" title="铁皮房违建.占用公共通道." target="_blank" class="news14">铁皮房违建.占用公共通道.<font color="red">[图]</font></a>
可以发现不同的问题的链接不同的是 /日期/编号 ,因此便可以得到问题链接的正则表达式
/question/\d+/\d+\.shtml
二、数据分析
我们主要想要获取的数据是每一个问题中的名称,编号,以及问题详情和问题链接。这里主要是使用 xpath 来对网页中的内容进行解析。
<!-- 没有图片的 -->
<div class="pagecenter p3">
<div class="greyframe">
<div class="ctitle">
<div class="cleft"><strong class="tgray14"> 提问:路灯问题 编号:198526 </strong></div>
<div class="cright te12h2"></div>
<div class="clear"></div>
</div>
<div class="content text14_2">
<div class="c1 text14_2"> 清溪从三中台联厂到清风路土桥村那里的路灯已经有1个月没有开了,严重影响市民晚上出行以及存在安全隐患,请相关部门尽快解决,谢谢。</div>
<div class="line"></div>
<div class="audit"><div class="cleft">处理状态:<span class="qblue">已受理</span></div><div class="cright"><p class="te12h"> 网友:pcx肖 发言时间:2018-10-10 17:04:14 </p></div>
<div class="clear"></div>
</div>
<div class="line"></div>
<div class="shengming te12h">声明:以上留言仅代表网友个人观点,不代表本网站立场和观点。
</div>
</div>
</div>
</div>
<!-- 有图片的 -->
<div class="pagecenter p3">
<div class="greyframe">
<div class="ctitle">
<div class="cleft"><strong class="tgray14"> 提问:躁声严重扰民 编号:198522 </strong></div>
<div class="cright te12h2"></div>
<div class="clear"></div>
</div>
<div class="content text14_2">
<div class="c1 text14_2"> <div align="center" class="textpic"> <img src="/uploads/attached/2018/10/cb945033d6bd446e0769abd584ea2077.jpg"></div><div class="contentext"> 我要严重投诉!<br> 麻涌镇信鸿小区旁建强(泵车)工程机械租赁有限公司晚上躁声严重严重扰民,每到晚上10点开始一直到第二天早上7点泵车一直巨声轰隆隆的作响,超大的噪声严重影响到夜晚人们的休息,尤其会另一些本来睡眠少的老人家彻夜难眠。巨大的机器声音已令周围居民夜间休息苦不堪言,对身体健康造成很大影响! <br> <br> <br> 建强(泵车)工程机械租赁有限公司不能只考虑到自已的生产利益,也要考虑周围居民的正常基本的生活环境!<br> <br> 故恳请政府有关部门调查核实,敦促施建强(泵车)工程机械租赁有限公司停止夜间施工,保证住户的最基本的居住生活环境,使社区居民得以安居乐业! <br> <br> 谢谢</div></div>
<div class="line"></div>
<div class="audit"><div class="cleft">处理状态:<span class="qblue">已受理</span></div><div class="cright"><p class="te12h"> 网友:哈妹ing 发言时间:2018-10-10 16:55:58 </p></div>
<div class="clear"></div>
</div>
<div class="line"></div>
<div class="shengming te12h">声明:以上留言仅代表网友个人观点,不代表本网站立场和观点。
</div>
</div>
</div>
</div>
通过分析网页的源码便可以得到指定数据的 xpath 解析规则
- 问题名称和编号://div[@class=”pagecenter p3”]//strong[@class=”tgray14”]/text()
- 问题内容(有图)://div[@class=”contentext”]/text()
- 问题内容(无图)://div[@class=”c1 text14_2”]/text()
具体每一个网页的 url 可以通过对应的 response 的 url 属性来获取。
三、编程实现
1.创建项目
scrapy startproject sun0769Spider
cd sun0769Spider/sun0769Spider/spider
scrapy genspider -t crawl sun wz.sun0769.com
2.编写 items.py 文件
import scrapy
class Sun0769SpiderItem(scrapy.Item):
# 问题名称
question_name = scrapy.Field()
# 问题编号
question_number = scrapy.Field()
# 问题内容
question_text = scrapy.Field()
# 问题url
question_url = scrapy.Field()
3.编写 pipelines.py 文件
import json
class Sun0769SpiderPipeline(object):
def __init__(self):
"""
初始化操作,只执行一次
"""
# 打开json文件,用于保存数据,注意这里使用的也是self来访问的
self.file = open('sun0769.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 将item保存为文件
text = json.dumps(dict(item), ensure_ascii=False)+'\n'
# 写入本地
self.file.write(text)
# 将处理的数据输出
return item
def close_spider(self, spider):
"""
爬虫结束时执行,只执行一次
"""
self.file.close()
4.编写 sun.py 爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from sun0769Spider.items import Sun0769SpiderItem
class SunSpider(CrawlSpider):
name = 'sun'
allowed_domains = ['wz.sun0769.com']
start_urls = ['http://wz.sun0769.com/index.php/question/report']
# 获取网站下一个页面链接的处理规则,注意?需要使用转义字符来处理
link_next_page = LinkExtractor(allow=r'/question/report\?page=\d+')
# 获取页面中所有的问题的链接的处理规则
link_question = LinkExtractor(allow=r'/question/\d+/\d+\.shtml')
# 下面的规则载有一个请求响应到达时是同时进行处理的
rules = (
# 负责处理下一页数据的链接请求,
# 没有回调函数就不用写,直接使用对应的linkextractor找到链接发请求
# 没有callback则默认follow为true
Rule(link_next_page),
# 负责处理每页中问题的请求
Rule(link_question, callback='parse_item')
)
def parse_item(self, response):
"""
用来处理对应的问题
"""
item = Sun0769SpiderItem()
# 对响应文件进行xpath处理,获取所需的数据
question_info = response.xpath('//div[@class="pagecenter p3"]//strong[@class="tgray14"]/text()')[0].extract()
item['question_name'] = question_info.split(':')[1].split(' ')[0].strip()
item['question_number'] = question_info.split(' ')[-1].split(':')[-1].strip()
item['question_url'] = response.url
# 注意问题的具体内容分为有图和无图两种,并且返回的数据是列表可能有多个项,首先得将列表数据变换为字符串
content = response.xpath('//div[@class="contentext"]/text()').extract()
if len(content) is 0:
# 无图
content = response.xpath('//div[@class="c1 text14_2"]/text()').extract()
item['question_text'] = ''.join(content).strip()
else:
# 有图
item['question_text'] = ''.join(content).strip()
yield item
5.编写 settings.py 配置文件
# -*- coding: utf-8 -*-
# Scrapy settings for sun0769Spider project
BOT_NAME = 'sun0769Spider'
SPIDER_MODULES = ['sun0769Spider.spiders']
NEWSPIDER_MODULE = 'sun0769Spider.spiders'
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko',
}
ITEM_PIPELINES = {
'sun0769Spider.pipelines.Sun0769SpiderPipeline': 300,
}
6.启动项目
注意:启动项目时必须在项目对应的目录下执行下面的命令
scrapy crawl sun
7.观察结果
下面是所爬取到的部分数据,可以看到,爬虫是正确运行了的。
{"question_name": "路灯问题", "question_number": "198526", "question_url": "http://wz.sun0769.com/html/question/201810/388537.shtml", "question_text": "清溪从三中台联厂到清风路土桥村那里的路灯已经有1个月没有开了,严重影响市民晚上出行以及存在安全隐患,请相关部门尽快解决,谢谢。"}
{"question_name": "噪音扰民", "question_number": "198433", "question_url": "http://wz.sun0769.com/html/question/201810/388501.shtml", "question_text": "我要严重投诉! 桥头小学对面有家冻肉厂每到晚上12点开始一直到第二天早上机器一直巨声轰隆隆的作响,超大的噪声严重影响到夜晚人们的休息,尤其会另一些本来睡眠少的老人家彻夜难眠。巨大的机器声音已令周围居民夜间休息苦不堪言,对身体健康造成很大影响! 冻肉厂不能只考虑到自已的生产利益,也要考虑周围居民的正常基本的生活环境! 故恳请政府有关部门调查核实,敦促施冻肉厂停止夜间施工,保证住户的最基本的居住生活环境,使社区居民得以安居乐业! 谢谢!"}
{"question_name": "建筑嗓音扰民", "question_number": "198495", "question_url": "http://wz.sun0769.com/html/question/201810/388504.shtml", "question_text": "虎门镇武山沙一围土地公后面一建筑工地早上六点不到就开始发出非常大的声音,不知道是不是违建抢建的原因,严重影响附近居民和学生的睡眠和休息,希望有关部门管一管,还群众一个安静的环境,"}
{"question_name": "关于篁村广场周边规划问题", "question_number": "198496", "question_url": "http://wz.sun0769.com/html/question/201810/388505.shtml", "question_text": "请问,我查了一下篁村广场附近的规划图,那一大片规划都是空白。请问篁村广场附近的规划什么时候可以公布啊?谢谢。"}
{"question_name": "厚街镇宝塘村房屋普查负责人做事及其不到位", "question_number": "198498", "question_url": "http://wz.sun0769.com/html/question/201810/388507.shtml", "question_text": "房屋普查问题 有一天一个普查工作人员通过我家护工阿姨的手机打电话通知我 要带土地证回去管理区登记,我说屋主不是我,是我爸爸,他在香港工作,土地证不在我这里,工作人员说,可以拍土地证照片和身份证去登记。(当时不又没有明确说明照片的规范),而且我爸爸不会用手机传照片。第一次叫邻居帮他传了过来,我发过去,说不能这样照,要照白色那面纸。第二次照了白色那面纸,又说不行,然后才发了一个样板过来。我通过管理区问了负责人的电话,打电话过去问,这个负责人竟然一问三不知,一直说自己在外面干活,回去才给我答复,我说你今天就截止了,他说回去再了解情况。我第二次打电话过去问,第一张照片照了左边,第二张照片照了右边,能不能合在一起看就可以登记了,这个负责人又说他不了解情况,我无语。,当时通知我的时候那些工作人员没有人通知过我是为什么登记这个土地证,只是叫我交。通知一点也不到位。然后我问这个负责人,这个负责人直接挂我电话。过了半个小时打电话过来,说照片不行,给我建议叫我出去香港拿土地证回来村委会登记!!我说谁那么有空特意去香港拿土地证回来登记?他说这样我帮不到你,我说当时你的工作人员通知不到位为什么全部推卸责任,弄得村民这么麻烦。这个负责人还叫我拿出证据,说有什么证据他的工作人员通知不到位,我说要不要叫我家阿姨去管理区作证。我继续问他直接挂我电话。 我想问一下宝塘村的领导和镇府的领导,现在是不是任何什么人都可以做办公室负责人?一点办事能力也没有,面对村民的问题也是一问三不知。村民管理区不是一个为村民服务的社区吗,多问几个问题语气有点激动就说我发他脾气?反过来发我脾气挂电话?"}
{"question_name": "深圳户口的小朋友如何在东莞读公立小学", "question_number": "198499", "question_url": "http://wz.sun0769.com/html/question/201810/388508.shtml", "question_text": "您好! 我们全家人都是深圳户口,爸爸妈妈在东莞的企业上班,但是爸爸妈妈的社保是由深圳总公司在深圳代缴,没有在东莞缴社保,所以无法积分入学。那么在不把深圳户口迁到东莞来的情况下,深圳户口的小朋友要如何在东莞上公办小学呢?具体应该怎么操作?谢谢! 另外,之前咨询过教育局,教育局回复的内容如下: 转来咨询小孩转学问题的来信收悉,现回复如下: 为进一步解决新莞人子女接受义务教育问题,我市出台了《东莞市新莞人子女接受义务教育实施办法》,对新莞人子女入读我市公、民办学校作出明确规定。如来信人小孩需要到我市公办学校就读,建议登录东莞教育网http://www.dgjy.net“新莞人入学”专栏参阅有关信息(咨询电话:23126112)。 以上实施办法我们查询了一下,并没有解决我们的实际问题,烦请教育局尽可能回复的仔细一点,非常感谢!"}
{"question_name": "排污工程严重影响出行", "question_number": "198500", "question_url": "http://wz.sun0769.com/html/question/201810/388510.shtml", "question_text": "现在寮步横坑横西一路和附近路段都在实施排污工程,我就不明白了,一个百来米的路,搞个排污,要搞几个月;这是什么效率啊,难道责任部门就没有时效要求吗?也没有进度要求吗,也不考虑附近居民的日常生活吗?都是拍脑袋做事吗?如果是说是在荒山野地随你们搞多久都可以,也没人有意见,但是这是在小区边上,几个小区加起来有一、二千户居民,这样严重影响附近居民的日常出行;还没弄就把路给围起来,既然围起来了就要动,要动,就快点动,不要1天打鱼10天晒网,已经埋下去的,就赶快把路面恢复原样;现在搞得附近居民叫苦连天。希望快点结束"}
{"question_name": "外地户口能否免费领叶酸", "question_number": "198501", "question_url": "http://wz.sun0769.com/html/question/201810/388511.shtml", "question_text": "你好,听说东莞可以免费领6个月的叶酸,我去社保卡定点所在东城社区服务中心询问,工作人员说,只有夫妻其中一方是东莞本地户口才能免费领。没有本地户口要购买,请问外地户口在东莞真的规定不能免费领叶酸吗?"}
{"question_name": "入户东莞", "question_number": "198502", "question_url": "http://wz.sun0769.com/html/question/201810/388512.shtml", "question_text": "我在东莞有固定住房和工作,社保交了2年,大专毕业,请问还需要满足什么样的条件,才可以入户东莞?"}
{"question_name": "南阁大桥拆除对住在道滘富盈wo城的出行很不方便", "question_number": "198491", "question_url": "http://wz.sun0769.com/html/question/201810/388500.shtml", "question_text": "南阁大桥拆除对住在道滘富盈wo城的出行很不方便,住在富盈wo城的周边交通不便利,现在连唯一通往厚街的桥拆除重建,有考虑一下住在南阁大桥附近群众感受吗?本来上班五分钟的路程,桥一拆,足足多了将近十公里的路,给骑车上班的人带来很不便利。更何况周边没有一部通往厚街的公交车,交通是在差到离谱,请相关部门,能友善解决这个群众交通出行不便的问题。"}
{"question_name": "居民住宅区可以开二手车行吗!? 车辆就可以乱停吗!?", "question_number": "198490", "question_url": "http://wz.sun0769.com/html/question/201810/388499.shtml", "question_text": "东莞市道滘镇上梁洲村中安街有 东莞市新创汽车有限公司 ,其公司车辆多次堵塞村民村岛,影响村民出行,存在很大安全隐患。已向交警部门反映,交警反映未设置禁停标志或划设停车位,不能抄牌。请有关部门协作解决一下问题。另外,居民区可以办理营运执照?为什么居民区可以开二手车行?"}
{"question_name": "铁皮房违建.占用公共通道.", "question_number": "198507", "question_url": "http://wz.sun0769.com/html/question/201810/388517.shtml", "question_text": "铁皮房违建.占用公共通道.地址是樟木头石新管理区创业街36号后面的铁皮房属于违建.占用公共通道.已经同意自行拆除.一直到现在都没有动静.现在还把通道也赌上.道路也不能通行.如果发生火灾.后果十分不堪设想.已经投诉了几个月了.还没有得到结果.请有关部门快的处理为何.谢谢"}
{"question_name": "东莞东城倍康专科门诊不给患者药名", "question_number": "198504", "question_url": "http://wz.sun0769.com/html/question/201810/388514.shtml", "question_text": "在东莞东城阳光澳园旁边,东莞东城倍康门诊部看病不给患者药品名称,都是给的药粉,向护士要药品名称护士就故意写英文,明明药品都是有中文名称的,为什么不能给中文名称,给的英文名称根本查不到是什么药,患者几次吃的药都有过敏反应,已经来换了三次药,多次索要所开的药品名称是什么可就是不给,请东城食药监严查。给百姓一个公道。"}
查看作者信息
