Python3 爬虫(七):多线程爬虫
多线程
对于计算机而言,其需要处理一些比较复杂的任务时,一般来说是使用多线程或者多进程来进行处理。
CPU 一次执行一个进程,一个进程就代表程序的一次执行。而线程是在进程中的,一个进程至少包含一个线程。进程是 CPU 进程调度的基本单位。
但是对于什么时候使用多线程?什么时候使用多进程?其实是有相应的使用条件的:
多进程:主要适用与大规模的并行计算,因为一个进程就是一个任务,方便处理。
多线程:主要适用与大量并行I/O处理,而爬虫就是属于I/O处理的,所以爬虫一般都是使用的是多线程。
Python中的多线程
Python程序中实现多线程是通过导入 threading 模块来创建自定义的线程类来实现的。但是有一点需要注意的是:
Python 中有一个全局唯一的东西叫 GIL(全局解释器锁),其会保证在 Python程序中同时只有一个线程能够执行。因此对于 Python 来说其实是伪多线程的。
Python中的多进程适用于:大量密集的io处理
Python中的多线程适用于:大量密集的并行计算
Python中还有好多的异步网络加载框架,他们基本都是通过协程来实现的,比如:Scrapy 就是专门的异步网络框架。
多线程爬虫
在多线程爬虫的实现当中,最主要的需要使用多线程爬虫的地方其实是:爬取网页内容以及解析网页内容这两个部分。
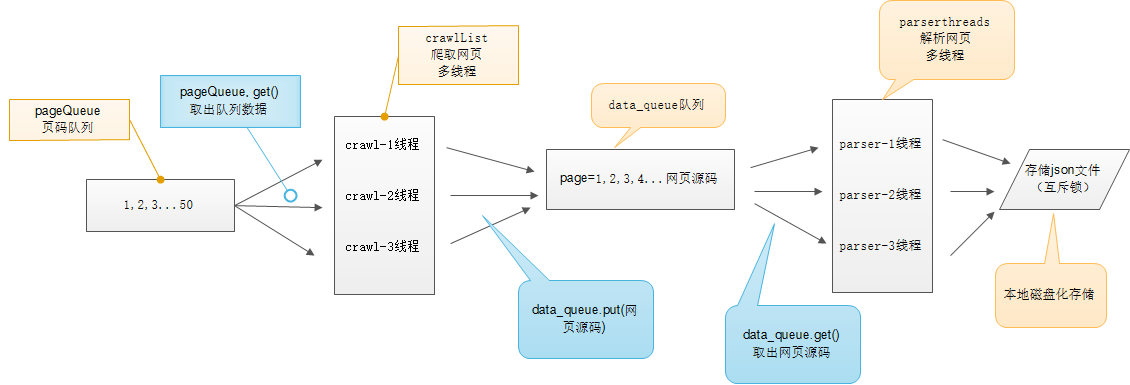
在爬取网页内容部分,需要使用多个爬虫来去爬取指定范围内的网页。为了保证程序的效率,便需要创建多个爬虫线程来去爬取。这时就涉及到一个每个爬虫爬取哪一页的问题。
爬取网页内容
这里解决的方式是通过一个 页码队列来进行相应的调度,使用队列来进行保存的原因是因为队列的 先进先出特性,可以保证对应页码的网页能被完整有序的保存下来。
将想要爬取的网页页码保存在该队列中,在创建相应数量的线程。对于每一个线程都可以对该队列中的网页进行处理,每次从队列中取出一个网页来进行爬取,由于 Python 是多线程安全的,所以可以不用担心线程堵塞的情况。当队列为空时,便证明所需要爬取的网页都已经全部爬去完毕。
解析网页内容
解析网页内容主要是通过 Xpath 等方式来对网页中重要的数据进行获取并进行相应的本地化。这里也可以通过使用多线程的方式来进行处理。为了保证多个线程之间处理数据不会产生冲突,这里也是使用了一个 网页队列来保存爬取到的网页数据,按照队列先进先出的特性按照顺序来对队列中存储的每一个网页进行解析。
创建一定数量的解析网页线程,对于每一个线程来说,只要网页队列不为空的情况下便都可以进行相应的网页解析操作。直到网页队列为空为止,这时所需要的解析操作便已经结束了。
多线程爬虫爬取网页的过程如下图所示:
多线程实战:糗事百科爬取
思路
分析下糗事百科网站,其主要是一个静态网站,因此数据只要使用 get 请求获取到之后直接进行相应的 xpath 解析即可。主要问题就在于 xpath 解析规则的确定。
分析糗事百科的网页源码,找到每一条糗事百科所对应的div来分析:
<div class="article block untagged mb15 typs_long" id="qiushi_tag_120887034">
<div class="author clearfix">
<a href="/users/4055292/" target="_blank" rel="nofollow" style="height: 35px" onclick="_hmt.push(['_trackEvent','web-list-author-img','chick'])">
<img src="//pic.qiushibaike.com/system/avtnew/405/4055292/thumb/20180723212556.jpg?imageView2/1/w/90/h/90" alt="啊喂喂">
</a>
<a href="/users/4055292/" target="_blank" onclick="_hmt.push(['_trackEvent','web-list-author-text','chick'])">
<h2>
啊喂喂
</h2>
</a>
<div class="articleGender womenIcon">27</div>
</div>
<a href="/article/120887034" target="_blank" class="contentHerf" onclick="_hmt.push(['_trackEvent','web-list-content','chick'])">
<div class="content">
<span>
小侄子已经四岁了,今天回老家,我俩玩的正嗨,他突然冒出来一句:“姑姑我要拉臭臭!你不许跟过来!”呃~好吧[doge]<br>我跟弟妹说:“他这么大点儿的,会自己擦屁屁嘛?”弟妹很随意的说:“会!早会了,他上幼儿园开始就自己擦屁屁了!”<br>随着我若有所思“哦~”的一声,回头就看到刚从卫生间出来并趴在门框上的小侄子幽怨的眼神,牙缝里挤出来:“麻麻~我~好~像~忘~了~擦~屁~屁~~~”[捂脸][捂脸][捂脸]
</span>
</div>
</a>
<!-- 图片或gif -->
<div class="stats">
<!-- 笑脸、评论数等 -->
<span class="stats-vote"><i class="number">485</i> 好笑</span>
<span class="stats-comments">
<span class="dash"> · </span>
<a href="/article/120887034" data-share="/article/120887034" id="c-120887034" class="qiushi_comments" target="_blank" onclick="_hmt.push(['_trackEvent','web-list-comment','chick'])">
<i class="number">1</i> 评论
</a>
</span>
</div>
<div id="qiushi_counts_120887034" class="stats-buttons bar clearfix">
<ul class="clearfix">
<li id="vote-up-120887034" class="up">
<a href="javascript:voting(120887034,1)" class="voting" data-article="120887034" id="up-120887034" rel="nofollow" onclick="_hmt.push(['_trackEvent','web-list-funny','chick'])">
<i></i>
<span class="number hidden">489</span>
</a>
</li>
<li id="vote-dn-120887034" class="down">
<a href="javascript:voting(120887034,-1)" class="voting" data-article="120887034" id="dn-120887034" rel="nofollow" onclick="_hmt.push(['_trackEvent','web-list-cry','chick'])">
<i></i>
<span class="number hidden">-4</span>
</a>
</li>
<li class="comments">
<a href="/article/120887034" id="c-120887034" class="qiushi_comments" target="_blank" onclick="_hmt.push(['_trackEvent','web-list-comment01','chick'])">
<i></i>
</a>
</li>
</ul>
</div>
<div class="single-share">
<a class="share-wechat" data-type="wechat" title="分享到微信" rel="nofollow">微信</a>
<a class="share-qq" data-type="qq" title="分享到QQ" rel="nofollow">QQ</a>
<a class="share-qzone" data-type="qzone" title="分享到QQ空间" rel="nofollow">QQ空间</a>
<a class="share-weibo" data-type="weibo" title="分享到微博" rel="nofollow">微博</a>
</div>
<div class="single-clear"></div>
</div>
主要是获取其中发布糗事的用户姓名以及糗事内容,有发布图片也可以将对应图片的url保存下来,在获取每一个糗事所对应的点赞数和评论数。
注意:xpath 具有模糊方法,contains()模糊查询方法,第一个参数是要匹配的标签,第二个参数是标签名部分内容。通过该方法可以对某一个标签下的内容进行模糊匹配。
每一个糗事匹配规则:
# 总的糗事div
//div[contains(@class, "article block untagged")]
# 糗事作者信息:
.//h2
# 糗事内容:
.//div[@class="content"]/span
# 发表的图片信息:
.//div[@class="thumb"]//@src
# 点赞数:
.//span[@class="stats-vote"]/i
# 评论数:
.//a[@class="qiushi_comments"]/i
注意:xpath返回的是一个列表,因此匹配成功取值的话是使用角标的方式来取
在了解了糗事百科网站网页的匹配规则之后便可以进行编写代码的工作了。
代码
"""
多线程爬虫实战:糗事百科爬取
"""
# 导入所需要的对应模块
import threading
import json
import requests
from lxml import etree
from queue import Queue
# 全局变量
# 控制爬取以及解析线程结束条件
CRAWL_EXIT = False
PARSE_EXIT = False
# 所要爬取网站的基本url
URL = 'https://www.qiushibaike.com/8hr/page/'
class ThreadCrawl(threading.Thread):
"""
网页爬取线程,负责对网页队列中的页面进行爬取
"""
def __init__(self, thread_name, page_queue, html_queue):
# 首先线程类得先调用父类的初始化方法
# 这里调用父类的方法有两种方式:
# 一种是:threading.Thread.__init(self)
# 另一种是:super(ThreadCrawl, self).__init__()
# 这两种方式的区别在只有一个父类的情况下是看不出来的
# 但是假如有多个父类的情况下,第一种方式只是调用了第一个父类的方式
# 而第二种方式便可以将所有的父类都进行调用
# 还有一个区别是在于修改代码的时候,第一种方式修改起来比较麻烦
# 而第二种便只用修改类中继承的父类名即可
# 因此,推荐使用第二种方式来进行父类方法调用
super(ThreadCrawl, self).__init__()
# 创建对应的类属性
self.thread_name = thread_name
self.page_queue = page_queue
self.html_queue = html_queue
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko'}
def run(self):
"""
启动线程,开始进行网页的爬取
:return:
"""
while not CRAWL_EXIT:
print(self.thread_name+'开始爬取网页')
try:
# 队列的get方法中有一个参数block,
# 默认为true,表示队列为空时阻塞程序,等待有数据进队列时再进行get操作
# 设置为false的话便不用使程序停下来,只是会抛出一个异常,因此需要进行异常捕获
page = self.page_queue.get(False)
# 构造请求url,并使用requests进行发送请求
url = URL+str(page)+'/'
# 注意requests使用的时候获取返回的内容是使用text属性而非方法
html = requests.get(url, headers=self.headers).text
# 将爬取下来的网页保存到队列中去
self.html_queue.put(html)
except Exception:
pass
print(self.thread_name+'网页爬取完成')
class ThreadParse(threading.Thread):
"""
网页解析线程,负责对爬取下来的网页进行解析
"""
def __init__(self, thread_name, html_queue, file, lock):
super(ThreadParse, self).__init__()
self.thread_name = thread_name
self.html_queue = html_queue
self.file = file
self.lock = lock
def run(self):
"""
启动线程,开始进行网页解析
:return:
"""
while not PARSE_EXIT:
print(self.thread_name+'开始进行解析')
try:
html = self.html_queue.get(False)
self.parse(html)
except Exception:
pass
print(self.thread_name+'解析结束')
def parse(self, html):
"""
处理html界面中的数据
:param html:
:return:
"""
# 将返回的网页信息转换为html dom模式
content = etree.HTML(html)
# 获取匹配结果,即为返回的一个糗事列表
qiushi_list = content.xpath('//div[contains(@class, "article block untagged")]')
# 创建一个字典来保存爬取的数据
content_list = {}
# 对每一个糗事信息进行处理
for text in qiushi_list:
# 用户名,取出内容之后并将其首尾的换行符去除
user_name = text.xpath('.//h2')[0].text.strip('\n')
# print(user_name)
# 糗事内容,text为取出标签里的内容,取出内容之后并将其首尾的换行符去除
con = text.xpath('.//div[@class="content"]/span')[0].text.strip('\n')
# print(con)
# 图片链接,注意,有些帖子有图片,有些没有
image_url = text.xpath('.//div[@class="thumb"]//@src')
# print(image_url)
# 点赞数
zan_number = text.xpath('.//span[@class="stats-vote"]/i')[0].text
# print(zan_number)
# 评论数
comment_number = text.xpath('.//a[@class="qiushi_comments"]/i')[0].text
# print(comment_number)
# 将每一条糗事中的数据保存到字典中去
content_list = {
'user_name': user_name,
'con': con,
'image_url': image_url,
'zan_number': zan_number,
'comment_number': comment_number
}
# with 后面有两个必须执行的操作:__enter__ 和 _exit__
# 不管里面的操作结果如何,都会执行打开、关闭
# 打开锁、处理内容、释放锁
with self.lock:
# 用追加的方式将字典中的内容保存到本地文件中
self.file.write(json.dumps(content_list, ensure_ascii=False) + '\n')
def main():
"""
主函数,负责主要功能流程实现
:return:
"""
# 页码队列,长度为10
page_queue = Queue(10)
# 将从1到10的数字保存到页码队列中去
for i in range(1, 11):
page_queue.put(i)
# 网页队列,长度为不限量
html_queue = Queue()
# 网页爬取线程集合,名称以及保存线程的集合
crawl_thread_name = ['爬取线程1', '爬取线程2', '爬取线程3']
crawl_thread_list = []
# 解析线程集合,名称以及保存线程的集合
parse_thread_name = ['解析线程1', '解析线程2', '解析线程3']
parse_thread_list = []
# 将解析到的数据以json的形式保存到本地文件里面
file = open('qiushi_data.json', 'a', encoding='utf-8')
# 为了保证文件保存到本地的时候不会出现顺序出错的情况,得给文件相关的读写操作加锁
lock = threading.Lock()
# 开始进行网页爬取,创建对应名称的线程并且启动,并将其保存起来
for crawl_thread in crawl_thread_name:
thread = ThreadCrawl(crawl_thread, page_queue, html_queue)
thread.start()
crawl_thread_list.append(thread)
# 开始进行网页解析
for parse_thread in parse_thread_name:
thread = ThreadParse(parse_thread, html_queue, file, lock)
thread.start()
parse_thread_list.append(thread)
# 先进行网页爬取,必须得等待所有的网页都爬取下来之后才能进行相应的网页解析
# 所以主线程得等待页面队列为空才能执行下一步,接下来便通知全局变量修改
# 让网页爬取线程可以停止工作了
while not page_queue.empty():
pass
global CRAWL_EXIT
CRAWL_EXIT = True
# 必须得将创建的线程加入到主线程中来,保证主线程等待子线程结束之后才退出,将其变为守护线程
for thread in crawl_thread_list:
thread.join()
# 程序必须等待解析线程执行完之后才能进行退出,因此程序必须得等待网页队列为空
# 在网页队列为空之后便可以进行通知全局变量,解析线程可以结束了
while not page_queue.empty():
pass
global PARSE_EXIT
PARSE_EXIT = True
# 必须得将创建的线程加入到主线程中来,保证主线程等待子线程结束之后才退出,将其变为守护线程
for thread in parse_thread_list:
thread.join()
# 程序结束,关闭文件
print('运行完成,谢谢使用')
with lock:
file.close()
if __name__ == '__main__':
main()
查看作者信息
