Python3 爬虫(十四):Scrapy 实战项目一:爬取斗鱼美女图片
使用 scrapy 来爬取斗鱼美女图片
数据来源分析
首先,我们要爬取的数据是斗鱼直播手机APP上的直播间照片。
因此,我们首先得对手机APP进行抓包操作,抓取到后台返回来的数据所对应的 json 文件信息。通过抓包分析,得到了下面的接口:
http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=
通过该接口只需要变换 offset 和 limit 的值便可以获取到所有的直播间信息
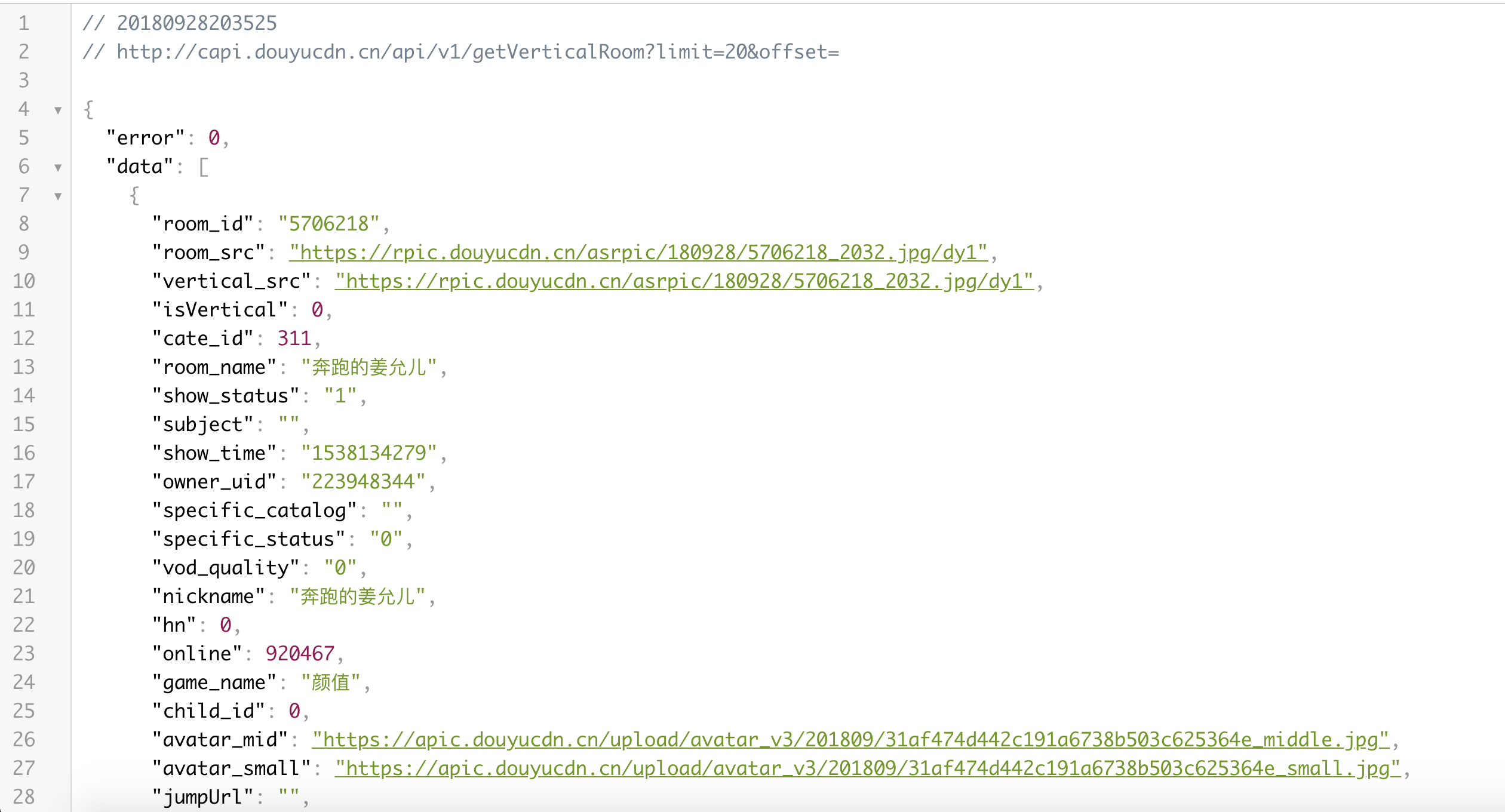
在获得了后台返回的数据之后我们爬虫的基本思路也就清晰了:
-
向该api发送请求,每一次将 offset 的内容加20
-
将返回的json数据转换为 python 字典类型,并取出其中需要的数据
-
将获得到的数据交给 pipeline 来进行下载
在确定了基本的思路之后便可以动手创建项目来爬取数据了。
爬取数据
新建项目
开始创建一个新的项目
python3 -m scrapy startproject douyuSpider
创建项目对应的爬虫文件
cd douyuSpider/douyuSpider/spiders/
python
3 -m scrapy genspider douyu_image_spider "capi.douyucdn.cn"
这样,便创建好了项目
编写 items 文件
首先根据后台传递回来的 json文件可以看到所需要保存的信息字段也就是 房间号、房间名、房间封面。
接下来定义 items 文件
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DouyuspiderItem(scrapy.Item):
# define the fields for your item here like:
# 房间号码
room_id = scrapy.Field()
# 房间名称
room_name = scrapy.Field()
# 房间封面图片
vertical_src = scrapy.Field()
编写爬虫文件
首先我们得明确爬虫文件所需要处理的任务:
-
发送第一页数据的请求
-
将第一页数据中的json文件转换为 python 字典类型,并将其封装为 DouyuspiderItem 对象
-
将封装好的 item 对象返回给 pipeline 去处理
-
继续发送 scrapy 请求来获取下一页的数据信息,直到获取不到数据为止
根据以上的内容我们便可以编写出来完整的爬虫来:
douyu_image_spider.py
import scrapy
import json
from douyuSpider.items import DouyuspiderItem
class DouyuImageSpiderSpider(scrapy.Spider):
name = 'douyu_image_spider'
allowed_domains = ['capi.douyucdn.cn']
page = 0
url = 'http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset='
start_urls = [url+str(page)]
def parse(self, response):
# 将返回的数据格式由json转换为字典类型,并取出其中data字段下的内容
rooms = json.loads(response.text)['data']
# 对每一个房间的数据进行处理
for room in rooms:
# 创建一个item对象
item = DouyuspiderItem()
item['room_id'] = room['room_id']
item['room_name'] = room['room_name']
item['vertical_src'] = room['vertical_src']
# 将item对象发送给pipeline去处理
yield item
# 开始处理下一页数据
self.page += 20
yield scrapy.Request(self.url+str(self.page), callback=self.parse)
编写 pipeline 管道处理文件
pipeline 管道处理文件主要是要保存图片到本地的,这里可以使用 scrapy 框架中的一个 ImagesPipeline 类。
scrapy 框架专门提供一个 item pipeline来保存图片,即ImagesPipeline,我们只需要重写一个管道继承ImagesPipeline,并且重写 get_media_requests(item, info)和 item_completed(results, items, info)这两个方法即可。
Pipeline 将从 item 中获取图片的 URLs 并下载它们,所以必须重载 get_media_requests,并返回一个 Request 对象,这些请求对象将被 Pipeline 处理,当完成下载后,结果将发送到item_completed 方法,这些结果为一个二元组的 list,每个元祖的包含(success, image_info_or_failure)。
success:boolean值,true表示成功下载 image_info_or_error:如果success=true,image_info_or_error词典包含以下键值对。失败则包含一些出错信息 url:原始 URL path:本地存储路径 checksum:校验码
pipelines.py
import os
import scrapy
from scrapy.pipelines.images import ImagesPipeline
# 导入如下类,可以对配置文件setting中的内容进行获取
from scrapy.utils.project import get_project_settings
class DouyuImagePipeline(ImagesPipeline):
"""
自定义imagepipeline处理管道,继承了ImagesPipeline
以下的方法为模版方法,用来对图片进行下载
"""
# 获取setting文件中设置的图片路径
IMAGES_STORE = get_project_settings().get('IMAGES_STORE')
# 开始对图片的url进行处理
def get_media_requests(self, item, info):
image_url = item['vertical_src']
# 去请求图片的url,并交给下面的方法来进行处理
yield scrapy.Request(image_url)
# 对已经下载好的图片信息进行处理
def item_completed(self, results, item, info):
# 提取图片的url信息,标准格式
image_path = [x["path"] for ok, x in results if ok]
# 将图片重新命名
os.rename(self.IMAGES_STORE + '/' + image_path[0], self.IMAGES_STORE+'/'+item['room_id']+'-'+item['room_name']+'.jpg')
# 更新图片路径
item['vertical_src'] = self.IMAGES_STORE+'/'+item['room_id']+'-'+item['room_name']
# 最后一定得将item返回
return item
编写配置文件
在上面的 pipelines 文件中就用到了 一个 设置文件中的 图片路径信息,这个信息是要求配置在 setting.py 文件中的。
而且,为了保证能够抓取到所需的数据信息,我们还需要使用专门的 user-agent 来访问api。这些都得在配置文件中编写。
setting.py
...
# 自定义图片下载路径,名称固定
IMAGES_STORE = '/home/wx/test/python/05-spider/day05/douyuSpider/images'
...
DEFAULT_REQUEST_HEADERS = {
# user-agent得为手机客户端抓包获取到的
"User-Agent" : "DYZB/1 CFNetwork/808.2.16 Darwin/16.3.0"
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
...
ITEM_PIPELINES = {
'douyuSpider.pipelines.DouyuImagePipeline': 300,
}
...
启动项目
默认的运行需要在命令行中执行 scrapy crawl spider_name,这样的缺点是不能在 IDE 里面debug 代码,比较不方便。所以,可以自己在项目里面新建一个run.py,以后执行这个文件就相当于启动爬虫。
run.py
from scrapy import cmdline
cmdline.execute("python3 -m scrapy crawl douyu_image_spider".split()) # 直接执行,log显示在控制台
# cmdline.execute("python3 -m scrapy crawl douyu_image_spider -s LOG_FILE=mzt.log".split()) # log保存在项目里面的mzt.log文件
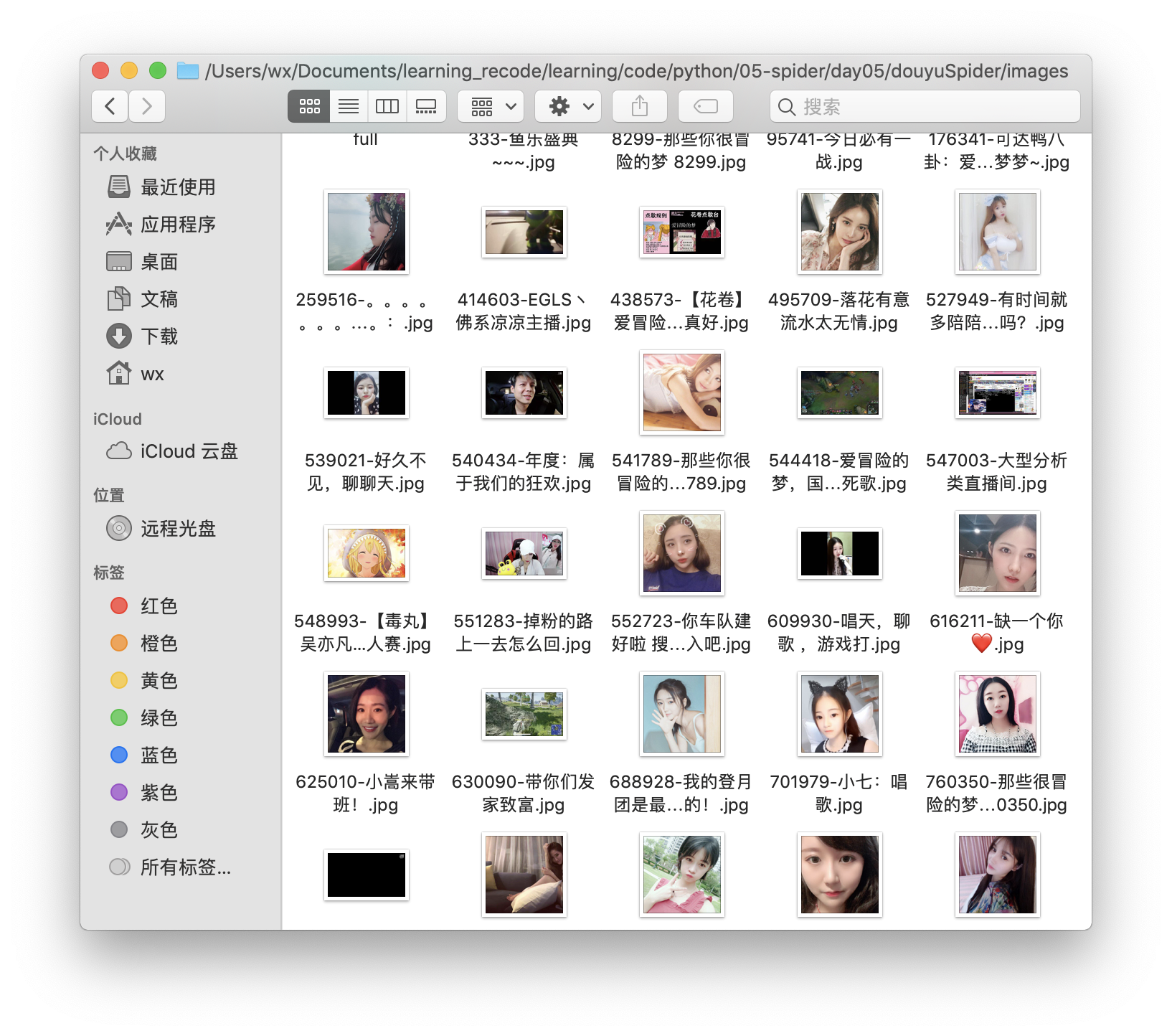
爬取结果
查看作者信息
