Python3 爬虫(十一):机器学习库 tesseract
tesseract
Tesseract,一款由 HP 实验室开发由 Google 维护的开源 OCR(Optical Character Recognition , 光学字符识别)引擎。通过 tesseract 可以不断的训练库,使图像转换文本的能力不断增强。如果团队深度需要,还可以以它为模板,开发出符合自身需求的OCR引擎。
tesseract 的官网tesseract
在爬虫当中,可以利用 tesseract 来帮助我们识别网站上的一些验证码,这样我们就不必像以前那样手动去识别验证码图片了。
tesseract 在使用之前需要首先训练一个图片识别的模型,将训练好的模型添加到系统的环境变量中去才可以进行相应的图片识别处理。附上练习使用的别人的数据模型:https://github.com/tesseract-ocr/tessdata_best
tesseract 安装
在 linux 上安装 tesseract 比较简单,只需要在命令行中输入如下的命令即可:
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev
tesseract 命令行使用
tesseract xxx.jpg result.txt -psm 7 digit
解释
tesseract 命令名
xxx.jpg 文件名,jpg,png都可以
result.txt 识别出的文字输出到文件
-psm 7 digit 参数
限定要识别的文字
例如要识别身份证号码,一般身份证号码为数字0到9还有大写的X,
加了限定以后,识别的准确率有所提升
例如识别身份证的一部分:
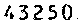
不加限定前,识别成1.3250
加了只能识别数字和X后,识别成:43250
具体方法:
打开tesseract安装目录,进入
tessdata/configs/
将digits复制一份,改名为:sfz,表示增加一份识别身份证规则的配置
使用文字编辑工具,打开文件sfz
在tessedit_char_whitelist 后面跟随要识别的字符
例如
tessedit_char_whitelist 0123456789X
保存退出
这个就是白名单,想识别的文字或者符号就写进去
识别的时候,需要在命令里加上sfz配置,例如
tesseract xxx.jpg result -psm 7 sfz
python代码:
import pytesseract
from PIL import Image
image = Image.open("../pic/c.png")
card_no = tess.image_to_string(cardImage,config='-psm 7 sfz')
print(card_no)
language的设置
此外,关于 image_to_string ,还有 langeuage 参数设定语言
code = pytesseract.image_to_string(image,lang="chi_sim",config="-psm 6")
语言叠加
还可以叠加语言包,例如你要识别的文字里,可能有中文和英文,可以这样设置:
code = pytesseract.image_to_string(image,lang="chi_sim+eng",config="-psm 6")
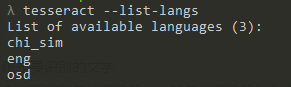
查看本地语言包
可以通过tesseract –list-langs查看本地语言包:
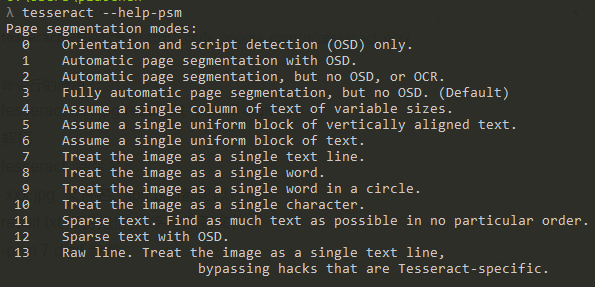
-psm的说明
关于config中 -psm 配置项的说明可以通过 tesseract –help-psm 查看psm
参考文章
https://blog.csdn.net/github_33304260/article/details/79155154?from=singlemessage
查看作者信息
