Python3 爬虫(五):BeautifulSoup4解析库
BeautifulSoup4解析库介绍
BeautifulSoup4 是 HTML/XML 的解析器,主要的功能便是解析和提取 HTML/XML 中的数据。
Python中用于爬取静态网页的基本方法/模块有三种:正则表达式、BeautifulSoup和Lxml。三种方法的特点大致如下:
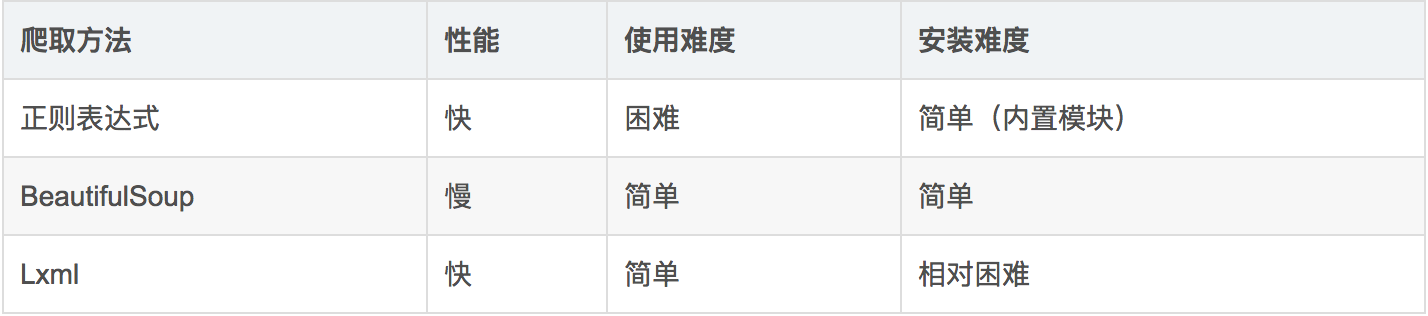
beautifulSoup 的功能和 lxml 一样,但是 lxml 只会局部遍历数据,而 BeautifulSoup是基于HTML DOM的,所以会载入整个文档来解析整个DOM树。因此在性能上来说 BeautifulSoup 是低于lxml 的。
安装 BeautifulSoup4:
在 python3 中安装 BeautifulSoup4 的方法如下:
pip3 install beautifulsoup4
BeautifulSoup4使用
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
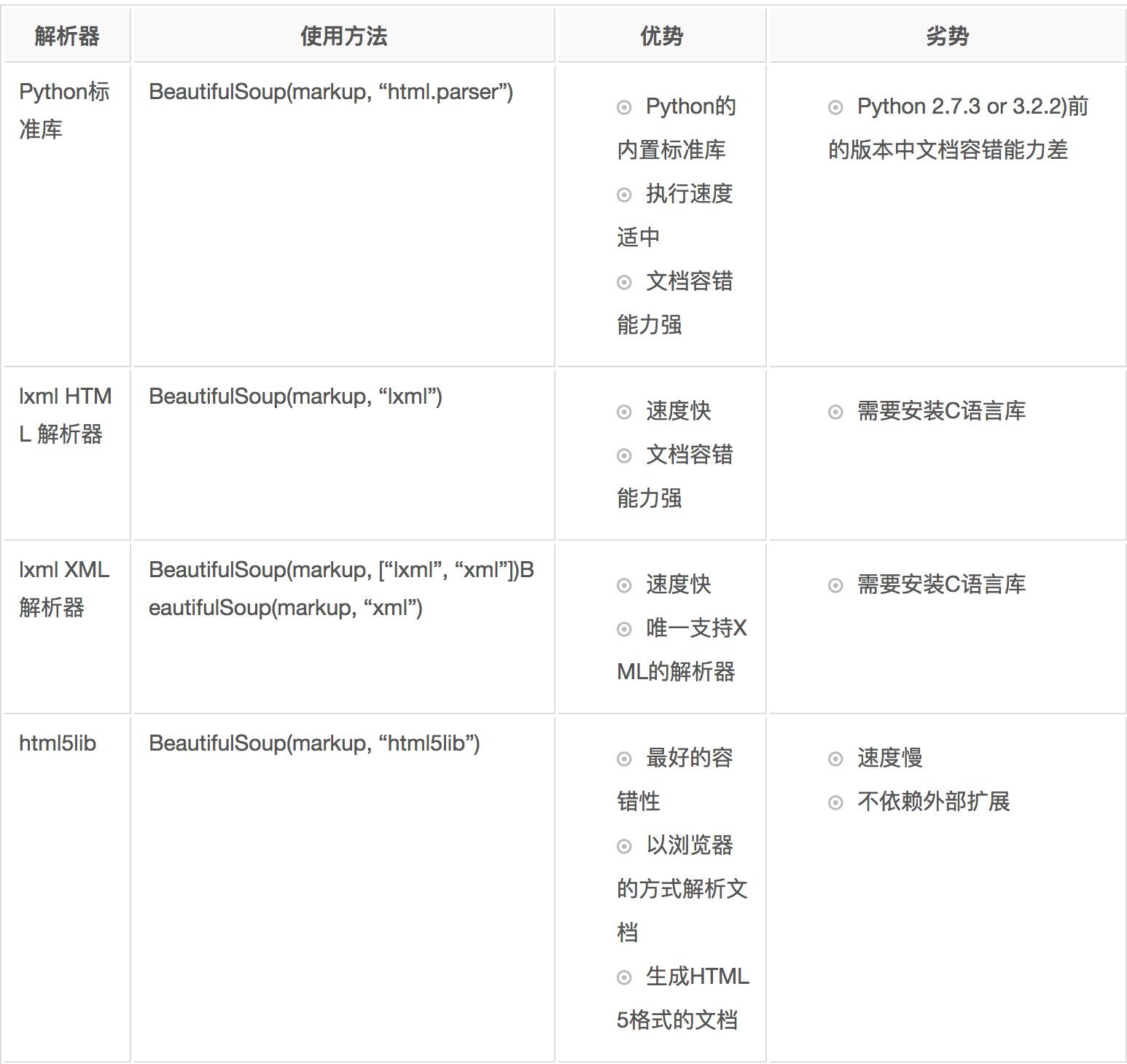
beautifulsoup的基本操作查看官方的文档即可: beautifulsoup4常用的操作总结
练习:模拟登陆西北工业大学翱翔门户
模拟登陆过程分析
1.首先需要从首页获取到所需登陆表单中的内容,由于目前网站都具有防跨域攻击的安全措施 因此,得获取到其相应的值。并且知乎还具有登陆的验证码,对于登陆验证码目前只能使用最基础的 操作:将其下载下来在手动输入来进行破解。这样,便获得到了登陆所需表单中的所有内容。
2.成功进行登陆之后便使用requests 中的 Session 来保存相应的登陆 cookie 值,有了相应的 登陆 cookie 值便可以进行之后的相应操作。
3.使用具有 cookie 值的 session 对象来获取登陆之后才能进行访问的界面的信息。
总的来说:对于任何的登陆模拟来说都是需要进行以上三步来进行的,区别在于不同的网站所需的登陆 表单参数不一样,这就需要进行相应的抓包来获取了。
需要用到的类库
在模拟登陆中需要使用到 requests第三方库,需要单独进行安装
pip3 install requests
代码
from bs4 import BeautifulSoup
import requests
import random
def get_headers():
"""
返回一个随机的user-agent
:return:
"""
ag_list = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"
]
return random.choice(ag_list)
def get_codeimage(image_data):
"""
保存验证码图片到本地,然后手动输入相应的值
:param image_data:
:return:
"""
# with open('codeimage.html', 'wb') as file:
# file.write(image_data)
codeimage = input('请输入验证码:')
return codeimage
def web_login(url):
"""
进行登陆操作
:return:
"""
# 创建session对象,其中可以保存用户登陆的cookies信息
session = requests.Session()
headers = {'User-Agent': get_headers()}
# 向url发送对应请求,首先获取登陆界面,同时会记录当前网页的cookies值
html = session.get(url, headers=headers).text
# 使用beautifulsoup来对返回的界面内容进行解析,调用lxml解析库,获取相应的内容
bs = BeautifulSoup(html, 'lxml')
# lt目的是为了防止CSRF攻击(跨站请求伪造),通常叫跨域攻击,是一种利用网站对用户的
# 一种信任机制(cookie机制)来做坏事。
# 跨域攻击通常利用cookie来通过伪装成网站信任的用户,来发送对应的请求来盗取用户信息或者欺骗服务器。
# 所以网站会通过设置一个隐藏字段来存放这个md5字符串,利用这个字符窜来校验用户cookie和服务器session
lt = bs.find('input', attrs={'name': 'lt'}).get('value')
# print(lt)
# 获取验证码图片的信息
headers = {'User-Agent': get_headers()}
code = random.random()*100
image_url = 'https://uis.nwpu.edu.cn/cas/codeimage?%d'%(code)
print(image_url)
image_data = session.get(image_url, headers=headers).content
codeimage = get_codeimage(image_data)
# 构造向服务器发送的表单数据
data = {
'username': '',
'password': '',
'imageCodeName': codeimage,
'errors': '0',
'lt': lt,
'_eventId': 'submit'
}
# 发送登陆请求
headers = {'User-Agent': get_headers()}
# 此处的登陆url有问题,暂时没有找到正确的登陆post对应的url,假如你找到了可以在评论区告诉我
response = session.post('https://uis.nwpu.edu.cn/cas/login', data=data, headers=headers)
print(response.text)
if __name__ == '__main__':
web_login('https://uis.nwpu.edu.cn/cas/login')
查看作者信息
