机器学习项目实战(一): Kaggle Titanic
Kaggle Titanic(泰坦尼克号幸存预测)
做为第一次参加 Kaggle 竞赛,因此选择了一个入门级的“泰坦尼克号幸存预”。之前一直是看《机器学习实用指南》这本书,这个竞赛也是这本书中的一道课后题。本教程使用 Scikit-Learn 来进行,由于是我第一个机器学习项目,因此只适合于初学者,大神请留下珍贵的建议。
首先在开始之前得明确一下机器学习的简单步骤:
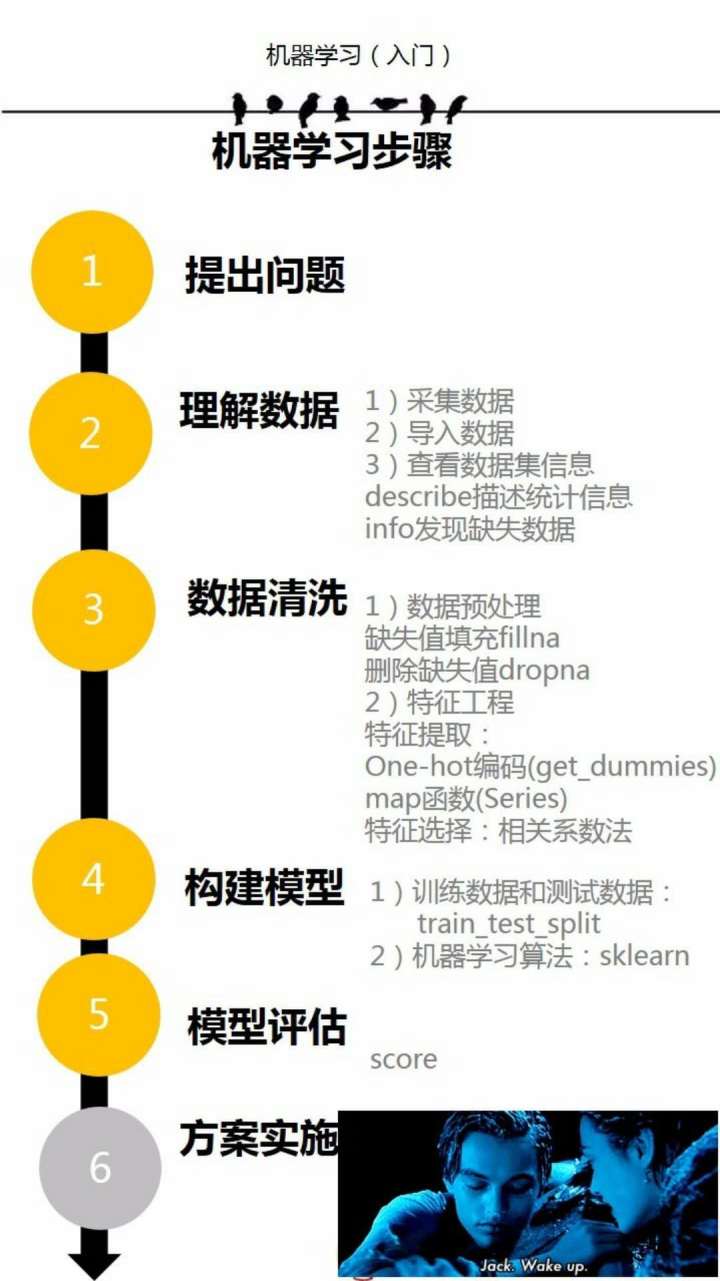
接下来按照这个步骤来一步步的进行处理
一、提出问题
Titanic是 Kaggle 上的一个竞赛。属于入门级比赛,在 Kaggle 提供的数据集中,共有1309名乘客数据,其中891是已知存活情况,剩下418则是需要进行分析预测的。
这项竞赛属于机器学习中的二元分类问题,为了获取到分析所需的数据,首先需要去 Kaggle 首页去创建一个账号,然后加入到Titanic竞赛中,从 Data 中下载所需要的数据。
下载的数据包括:
- gender_submission.csv:提交结果案例(提交结果)
- test.csv:测试数据
- train.csv:训练数据
二、理解数据
说到数据挖掘,是把散乱数据转换成「有价值」信息的过程,数据是可以是数字或者文本内容甚至图像,而信息是有语义的、人脑可理解的报告、图表。
数据分析的结果,就是把数字转化成人类可理解的信息。
先将所需的数据导入进来
train_set = pd.read_csv('./datasets/titanic/train.csv')
test_set = pd.read_csv('./datasets/titanic/test.csv')
接下来查看下数据:
train_set.head()

其中各列所代表的信息为:
- PassengerId:乘客的ID(对预测没有用处)
- survival:是否存活,0表示死亡,1表示存活
- pclass:船票的类别,可以用来表示乘客的经济情况,1 = 1st, 2 = 2nd, 3 = 3rd
- sex:乘客性别
- Age:乘客年龄
- sibsp:船上兄弟姐妹及配偶的个数
- parch:船上父母或子女的个数
- ticket:船票号
- fare:船票价格
- cabin:客舱号码
- embarked:登船口岸,C = Cherbourg, Q = Queenstown, S = Southampton
查看数据的基本信息:
train_set.info()
可以看到,Age、Cabin、Embarked 这几个属性都具有缺失值,其中 Cabin 缺失的最严重,具有缺失值的都要在数据清洗中进行处理。

再来看一下训练集中数字类型特征的统计信息
train_set.describe()
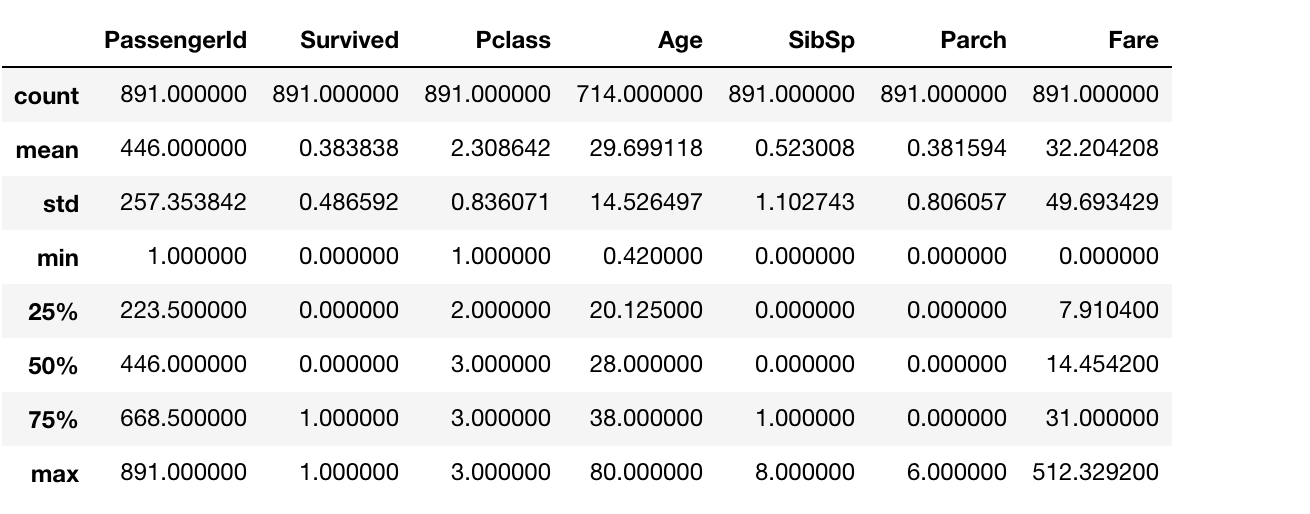
对数据进行简单的预览来了解数据,这为我们下一步数据清洗指明了方向,只有知道哪些数据缺失数据,哪些数据存在问题,我们才能有针对性的处理。
三、数据清洗
数据清洗操作包括 数据预处理 以及 特征工程两个部分,数据清洗是机器学习中最重要最耗时的部分,经常需要多次反复的进行,这里可以使用 Scikit-learn 中提供的 pipeline 管道来同时进行这两部操作。
1.数据预处理
对于具有缺失值的特征数据来说,一般的处理方式包括 将缺失值填充 或者 删除具有缺失值的数据。这里我们使用填充的方式来处理具有缺失值的数据。
根据缺失的数据是数字还是非数字所对应的填充策略也不一样。
对于数字数据 Age、Fare 来说是使用其数据的中位数来进行填充。
而非数字数据包括:Embarked(港口数据)以及 Cabin(船舱号),港口数据只两个缺失值,我们将缺失值填充为最频繁出现的值:S=英国南安普顿 Southampton;而船舱号缺失数据比较多,我们不使用改特性来进行预测。
2.特征工程
特征工程是整个机器学习过程中最重要的阶段,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
我们需要通过探索数据,利用先验知识,从数据中总结出特征。
那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。通过总结和归纳,人们认为特征工程包括以下方面:
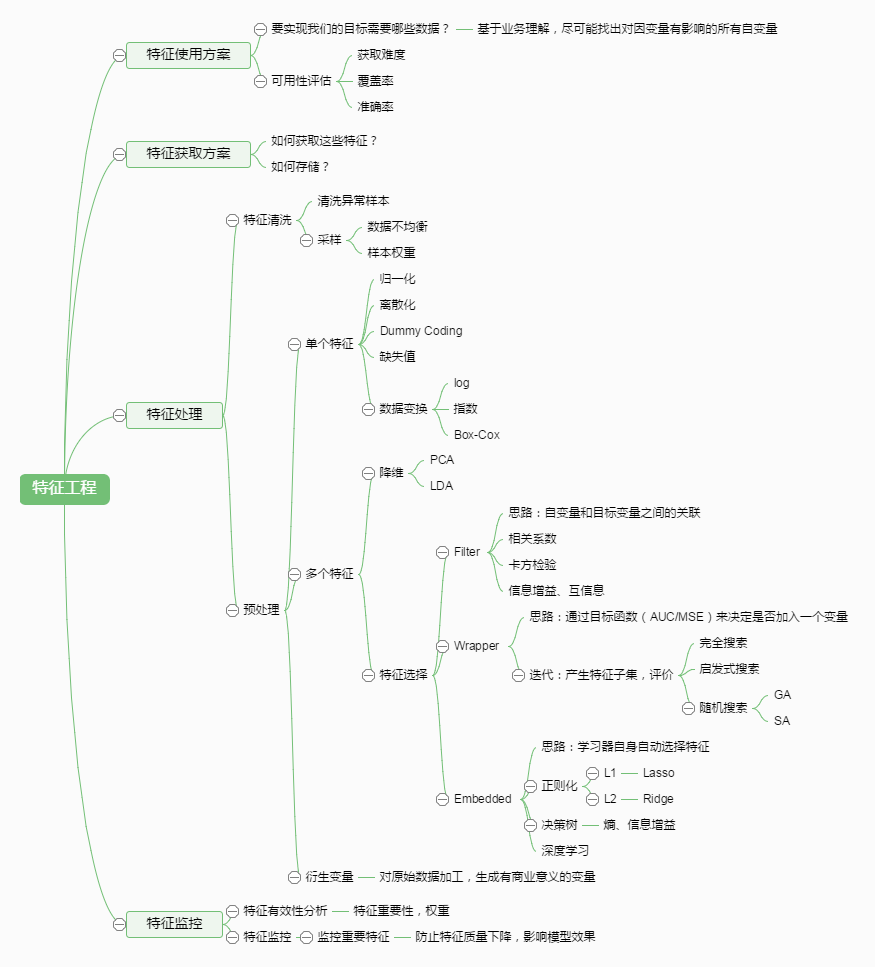
特征处理是特征工程的核心部分,sklearn 提供了较为完整的特征处理方法,包括数据预处理,特征选择,降维等。
这里我们选择 “Age”, “SibSp”, “Parch”, “Fare”, “Pclass”, “Sex”, “Embarked” 这几个特性来进行预测。(这里选择的特征是书上选择的,一般来说可以通过查看特征与预测特征的依赖关系来选择)
首先编写一个类来将指定的特征从数据集中选择出来
from sklearn.base import BaseEstimator, TransformerMixin
# A class to select numerical or categorical columns
# since Scikit-Learn doesn't handle DataFrames yet
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names]
首先将数字类型选择出来,并将其中有缺失值的部分进行填充,这里使用 Scikit-learn 中的管道
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import Imputer
# 按中位数进行填充
imputer = Imputer(strategy="median")
num_pipeline = Pipeline([
("select_numeric", DataFrameSelector(["Age", "SibSp", "Parch", "Fare"])),
("imputer", Imputer(strategy="median")),
])
来查看下管道的处理结果
num_pipeline.fit_transform(train_set)

接下来对非数字类型的特性进行数据清洗,首先对具有缺失数据的数据填充为其中出现最多的值,并将其表示为 OneHot 数字类型的格式。
class MostFrequentImputer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
self.most_frequent_ = pd.Series([X[c].value_counts().index[0] for c in X],
index=X.columns)
return self
def transform(self, X, y=None):
return X.fillna(self.most_frequent_)
from future_encoders import OneHotEncoder
cat_pipeline = Pipeline([
("select_cat", DataFrameSelector(["Pclass", "Sex", "Embarked"])),
("imputer", MostFrequentImputer()),
("cat_encoder", OneHotEncoder(sparse=False)),
])
查看下管道处理的结果
cat_pipeline.fit_transform(train_set)

四、构建模型
在构建模型之前先得获取到训练模型所需的训练数据,包括训练输入数据以及相对应的训练输出数据。
1.获取训练数据
将上述的管道操作组合为一个完整的管道处理
# 将数据的清洗操作做为一个完整的管道操作来进行
from sklearn.pipeline import FeatureUnion
preprocess_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline),
])
来对测试数据进行上述的管道操作,得到最后的输入训练数据
X_train = preprocess_pipeline.fit_transform(train_set)
X_train
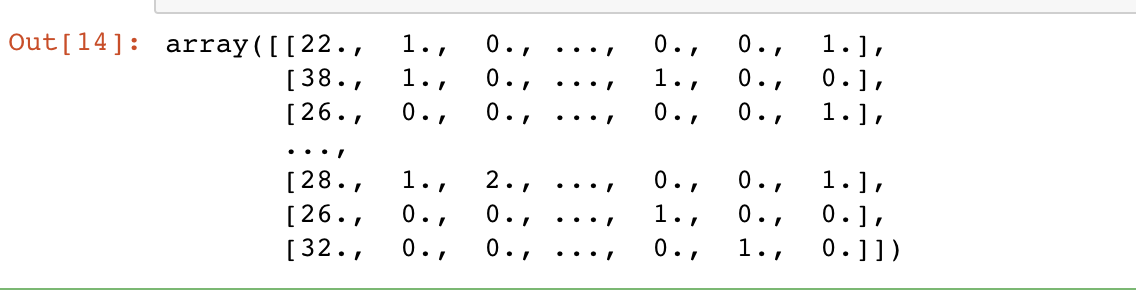
在来获取输出的训练数据
y_train = train_set['Survived'] == 1
2.构建模型
模型这里选择的是 RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
forest_clf.fit(X_train,y_train)
五、模型评估
查看模型的准确性
forest_clf.score(X_train,y_train)

六、方案实施
接下来便使用我们创建的模型来对测试数据进行预测
# 对测试数据集进行相同的数据预处理管道操作
X_test = preprocess_pipeline.fit_transform(test_set)
# 使用模型对数据进行预测
y_test = forest_clf.predict(X_test)
# 乘客id
passenger_id = test_set['PassengerId']
# 预测结果转换为int类型
y_test = y_test.astype(int)
# 将结果做为新的数据保存
pred_df = pd.DataFrame(
{ 'PassengerId': passenger_id ,
'Survived': y_test } )
pred_df.shape
# 保存到本地
pred_df.to_csv("./datasets/titanic/prediction.csv", index=False)
将最后生成的结果提交到 Kaggle 上看一下自己的排名吧。
参考文章地址
- https://zhuanlan.zhihu.com/p/33565306
- https://zhuanlan.zhihu.com/p/27655949
- http://www.cnblogs.com/jasonfreak/p/5448385.html
查看作者信息
