eBPF(一):简介
目录:
eBPF 简介
BPF 的全称是 Berkeley Packet Filter,顾名思义,这是一个用于过滤(filter)网络报文(packet)的架构。
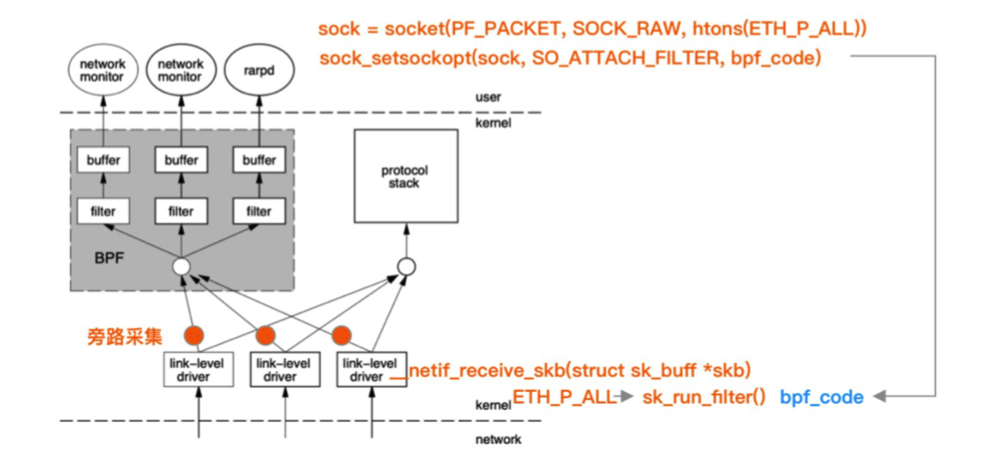
BPF 采用的报文过滤设计的全称是 CFG(Computation Flow Graph),顾名思义是将过滤器构筑于一套基于 if-else 的控制流(flow graph)之上
BPF 被引入 Linux 之后,除了一些小的性能方面的调整意外,很长一段时间都没有什么动静。直到 3.0 才首次迎来了比较大的革新:在一些特定硬件平台上,BPF 开始有了用于提速的 JIT(Just-In-Time) Compiler。
自 3.15 开始,一个套源于 BPF 的全新设计开始逐渐进入人们的视野,并最终(3.17)被添置到了 kernel/bpf 下。这一全新设计最终被命名为了 extended BPF(eBPF):顾名思义,有全面扩充既有 BPF 功能之意;而相对应的,为了后向兼容,传统的 BPF 仍被保留了下来,并被重命名为 classical BPF(cBPF)。
eBPF 相对于 cBPF 的增强如下:
- 处理器原生指令集建模,因此更接近底层处理器架构, 性能相比 cBPF 提升 4 倍;
- 指令集从 33 个扩展到了 114 多个,依然保持了足够的简洁;
- 寄存器从 2 个 32 位寄存器扩展到了 11 个 64 位的寄存器 (其中 1 个只读的栈指针);
- 引入 bpf_call 指令和寄存器传参约定,实现零(额外)开销内核函数调用;
- 虚拟机的最大栈空间是 512 字节(cBPF 为 16 个字节);
- 引入了 map 结构,用于用户空间程序与内核中的 eBPF 程序数据交换;
- 最大指令数初期为 4096,现在已经将这个限制放大到了 100 万条;
eBPF的优点:
- 稳定:有循环次数和代码路径触达限制,保证程序可以固定时间结束;
- 高效:可通过 JIT 方式翻译成本地机器码,执行效率高效;
- 安全:验证器会对 eBPF 程序的可访问函数集合和内存地址有严格限制,不会导致内核 Panic;
- 热加载/卸载(持续交付):可热加载/卸载 eBPF 程序,无需重启 Linux 系统;
- 内核内置:eBPF 自身提供了稳定的 API;
eBPF的缺点:
- eBPF程序不能调用任意的内核函数,只限于内核模块中列出的BPF辅助函数,函数支持列表也随着内核 的演进在不断增加;最新进展是支持了直接调用特定的内核函数调用;
- eBPF程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止;
- eBPF程序中循环次数限制且必须在有限时间内结束,Linux5.3在BPF中包含了对有界循环的支持,它 有一个可验证的运行时间上限;
- eBPF堆栈大小被限制在MAX_BPF_STACK,截止到内核Linux5.8版本,被设置为512eBPF字节码大小最 初被限制为 4096 条指令,截止到内核 Linux 5.8 版本, 当前已将放宽至 100 万指令 ,对于无特权的 BPF 程序,仍然保留 4096 条限制 (BPF_MAXINSNS);新版本的 eBPF 也支持了多个 eBPF 程序级联调用, 可以通过组合实现更加强大的功能;
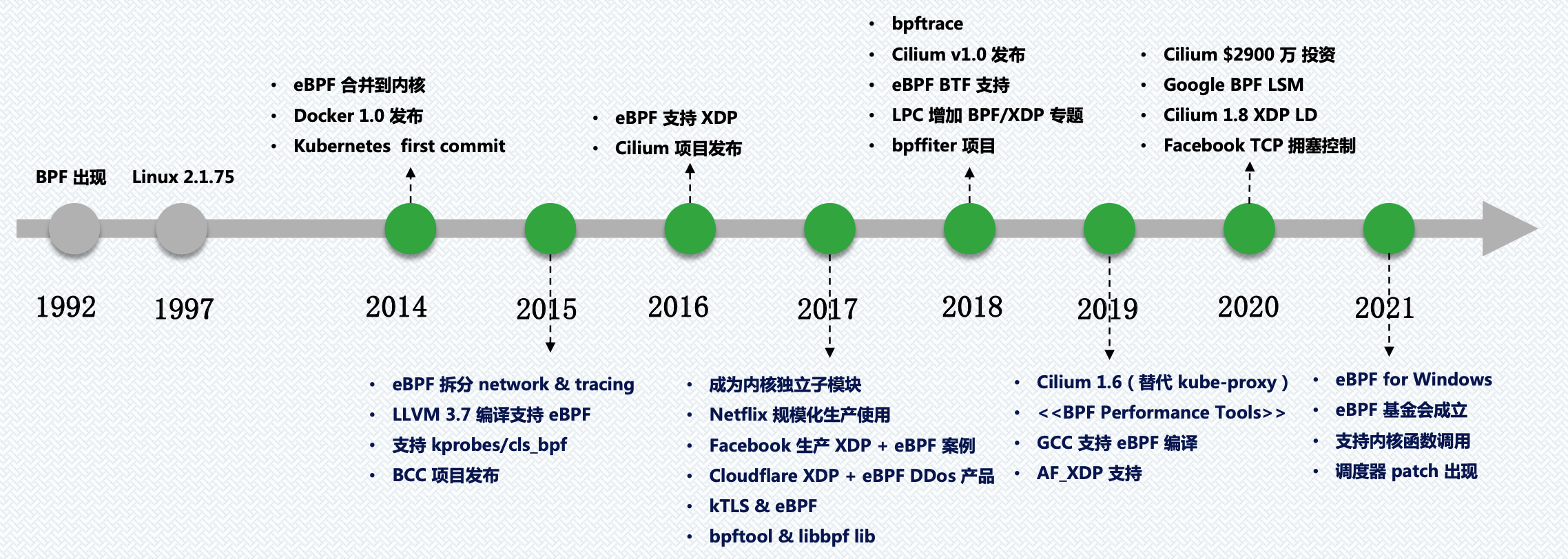
eBPF的发展历史:
eBPF 应用场景
eBPF 主要的应用场景主要分为三类:
- Networking:网络
- Security:安全
- Observability&Tracing:观测与追踪
这里主要介绍 Observability&Tracing:观测与追踪 的相关知识:
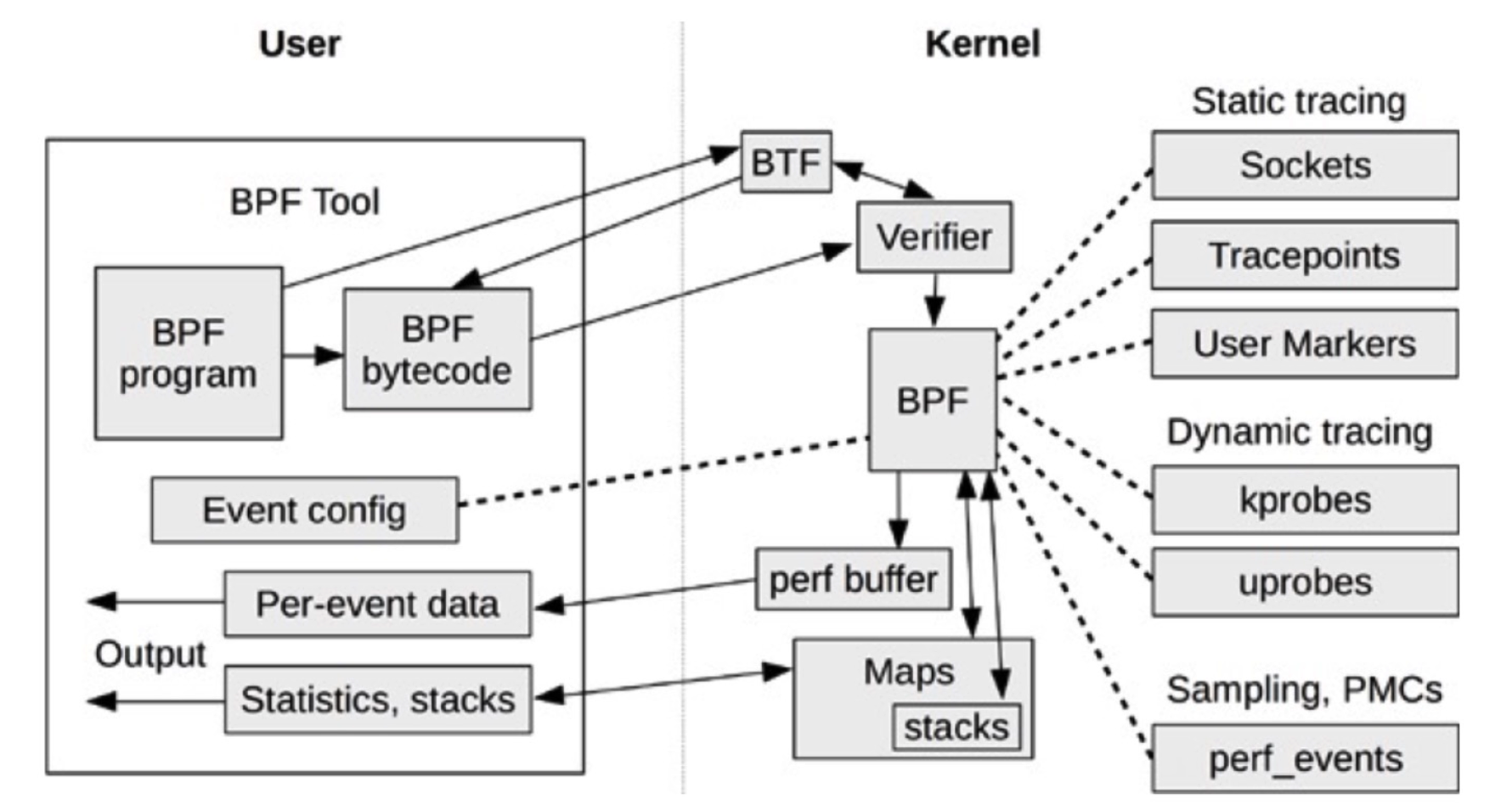
跟踪的事件对象支持:
- kprobes/kretprobes:实现内核中动态跟踪。 可跟踪 Linux 内核中的函数入口或返回点,非稳 定 ABI 接口;(5.5 fentry/fexit 替代,性能和可用性更好)
- uprobes/uretprobes:用户级别的动态跟踪。与 kprobes 类似,只是跟踪的函数为用户程序中 的函数;
- tracepoints:内核中静态跟踪。tracepoints 是内核开发人员维护的跟踪点,能够提供稳定的 ABI 接口,但是由于是研发人员维护,数量和场景可能受限;
- perf_events:定时采样和 PMC;
对于内核文件 /proc/kallsyms 暴露的函数列表,都可以认为使用 kprobes 进行跟踪,内核中 inline 的函数和部分明确屏蔽 kprobe 跟踪的函数无法跟踪,可以理解基本上 Linux 的内核所有函 数都可使用 kprobe 跟踪,当前 5.x 内核中导出函数数量在 13万+。
常见的一些性能追踪工具可以使用 bcc 提供的工具:

其中追踪会涉及到一些内核中的调用路径,可以通过这里查看:https://makelinux.github.io/kernel/map/
eBPF 工作原理

eBPF的工作原理:
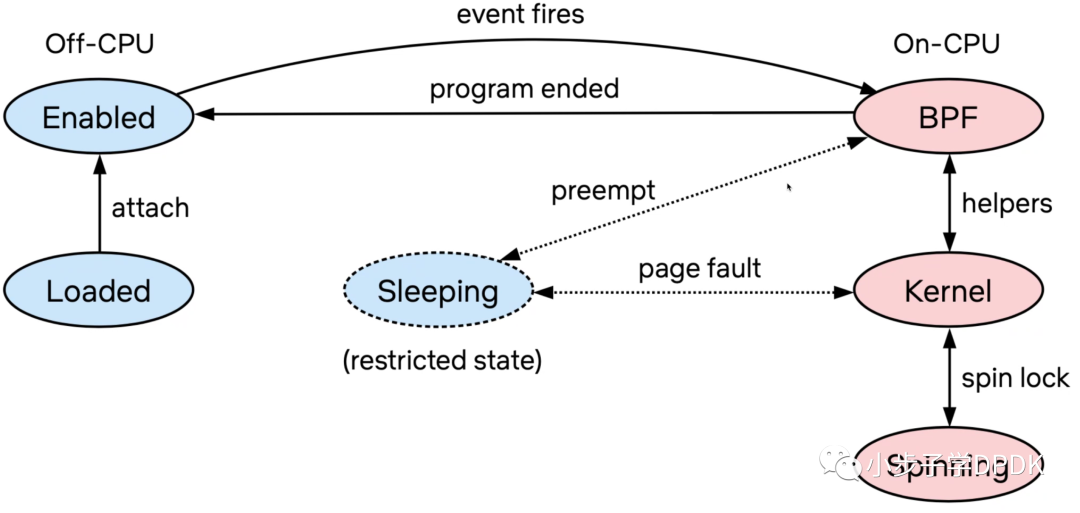
先load,并且enable写好的BPF字节码,当event(kprobes, tracepoint等)触发时,会运行BPF代码。
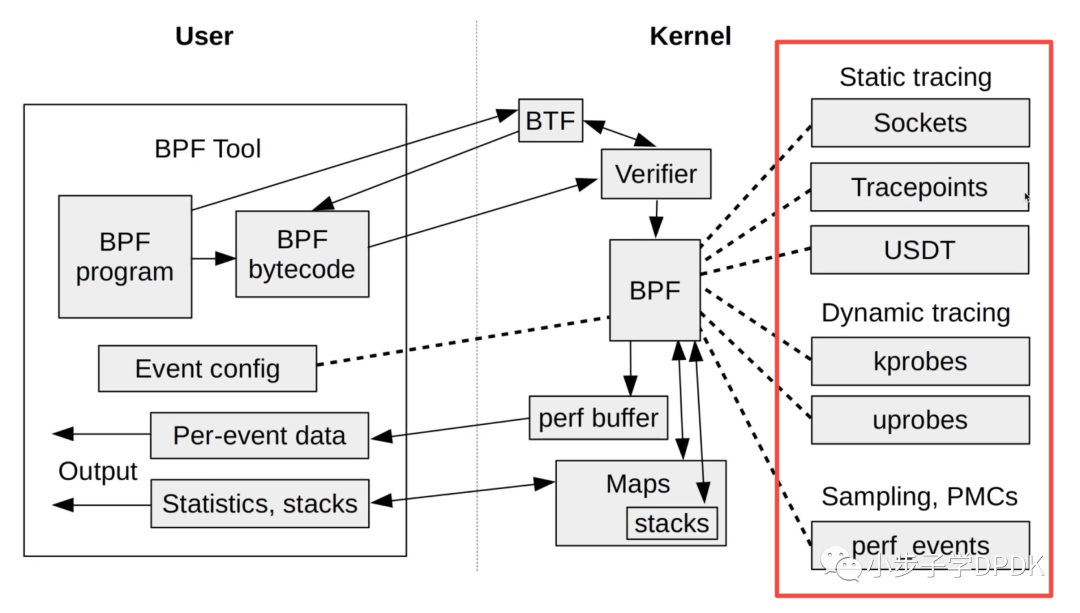
内核态的BPF会attach到用户态的event config。支持静态,动态trace,以及perf PMC的采样。其中的BPF map可异步传给用户态数据,或者BPF程序内交换数据。类型在kernel的struct bpf_map结构体中定义。
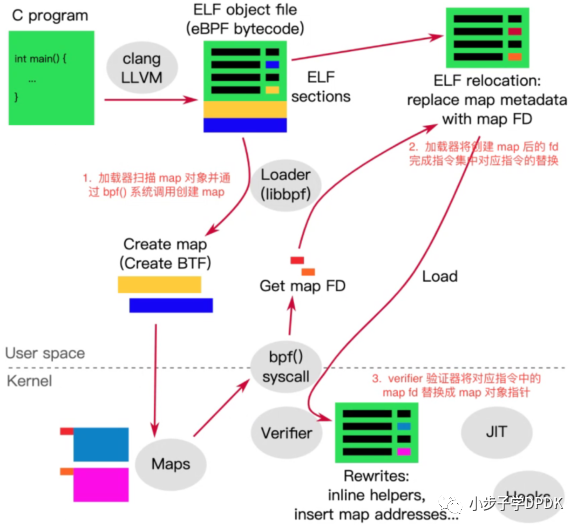
bpf_prog_load()函数会校验license,判断BPF指令个数,太多就不让执行,判断权限,把BPF字节码从用户态加载到内核,bpf_check()进行verifier校验,bpf_prog_select_runtime()进行JIT编译,分配id和文件句柄。
可以看到,libbpf是一个loader,把BPF代码加载到内核。
如何开发 eBPF 工具
eBPF 工具的形态
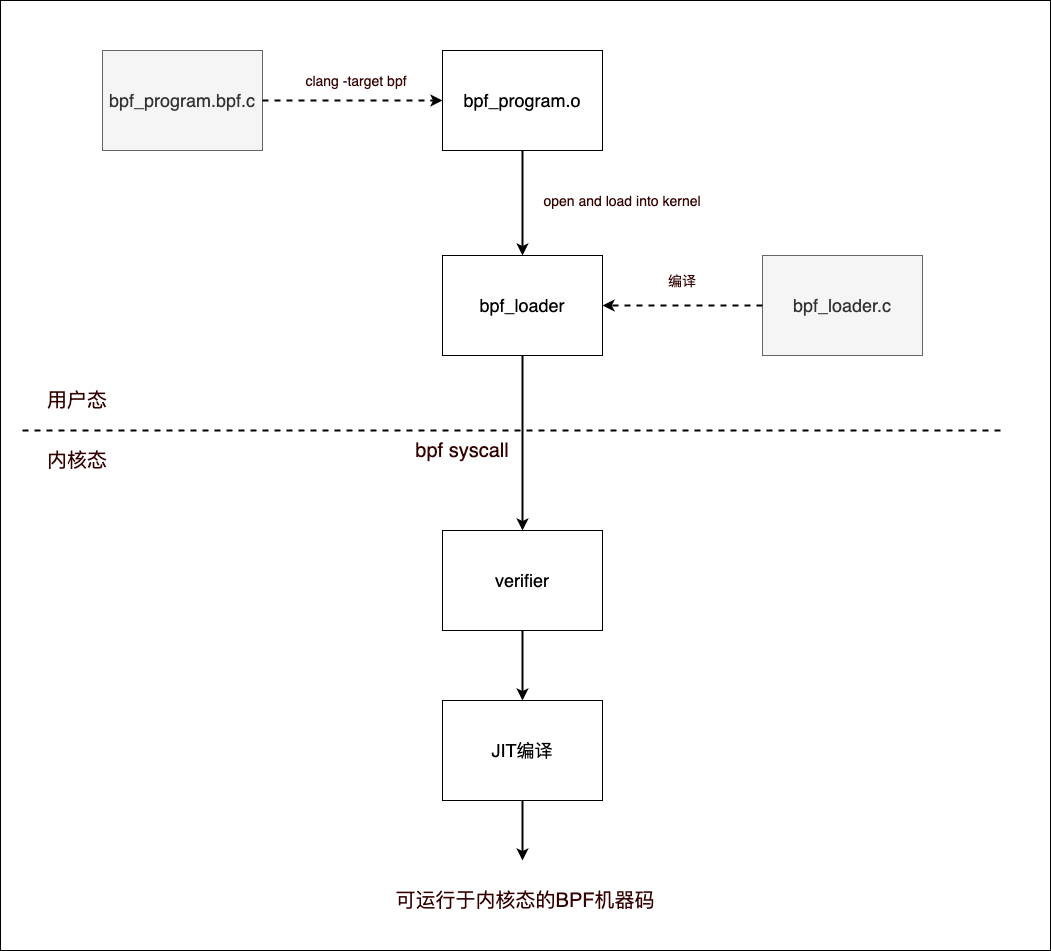
一个 eBPF 工具主要由两类源文件组成,一类是运行于内核态的 BPF 程序的源代码文件(比如:下图中bpf_program.bpf.c)。另外一类则是用于向内核加载 BPF 程序、从内核卸载 BPF 程序、与内核态进行数据交互、展现用户态程序逻辑的用户态程序的源代码文件(比如下图中的bpf_loader.c)。
目前运行于内核态的 BPF 程序只能用 C 语言开发(对应于第一类源代码文件,如下图 bpf_program.bpf.c),更准确地说只能用受限制的 C 语法进行开发,并且可以完善地将 C 源码编译成 BPF 目标文件的只有clang 编译器。
下面是 BPF 程序的编译与加载到内核过程的示意图:
BPF 目标文件(bpf_program.o)实质上也是一个ELF格式的文件,我们可以通过 readelf 命令行工具可以读取 BPF 目标文件的内容,下面是一个示例:
$readelf -a bpf_program.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Linux BPF
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 424 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 8
Section header string table index: 1
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .strtab STRTAB 0000000000000000 0000012a
0000000000000079 0000000000000000 0 0 1
[ 2] .text PROGBITS 0000000000000000 00000040
0000000000000000 0000000000000000 AX 0 0 4
[ 3] tracepoint/syscal PROGBITS 0000000000000000 00000040
0000000000000070 0000000000000000 AX 0 0 8
[ 4] .rodata.str1.1 PROGBITS 0000000000000000 000000b0
0000000000000012 0000000000000001 AMS 0 0 1
[ 5] license PROGBITS 0000000000000000 000000c2
0000000000000004 0000000000000000 WA 0 0 1
[ 6] .llvm_addrsig LOOS+0xfff4c03 0000000000000000 00000128
0000000000000002 0000000000000000 E 7 0 1
[ 7] .symtab SYMTAB 0000000000000000 000000c8
0000000000000060 0000000000000018 1 2 8
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
p (processor specific)
There are no section groups in this file.
There are no program headers in this file.
There is no dynamic section in this file.
There are no relocations in this file.
The decoding of unwind sections for machine type Linux BPF is not currently supported.
Symbol table '.symtab' contains 4 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS bpf_program.c
2: 0000000000000000 4 OBJECT GLOBAL DEFAULT 5 _license
3: 0000000000000000 112 FUNC GLOBAL DEFAULT 3 bpf_prog
在上面 readelf 输出的符号表(Symbol table)中,我们看到一个 Type 为 FUNC 的符号 bpf_prog,这个就是我们编写的 BPF 程序的入口。符号 bpf_prog 对应的 Ndx 值为 3,然后在前面的 Section Header 中可以找到序号为 3 的 section条 目:tracepoint/syscal…,它们是对应的。
从 readelf 输出可以看到:bpf_prog(即序号为3的section)的 Size 为112,但是它的内容是什么呢?这个 readelf 提示无法展开 linux BPF 类型的 section。
我们使用另外一个工具 llvm-objdump 将 bpf_prog 的内容展开:
$llvm-objdump-10 -d bpf_program.o
bpf_program.o: file format ELF64-BPF
Disassembly of section tracepoint/syscalls/sys_enter_execve:
0000000000000000 bpf_prog:
0: b7 01 00 00 21 00 00 00 r1 = 33
1: 6b 1a f8 ff 00 00 00 00 *(u16 *)(r10 - 8 ) = r1
2: 18 01 00 00 50 46 20 57 00 00 00 00 6f 72 6c 64 r1 = 7236284523806213712 ll
4: 7b 1a f0 ff 00 00 00 00 *(u64 *)(r10 - 16) = r1
5: 18 01 00 00 48 65 6c 6c 00 00 00 00 6f 2c 20 42 r1 = 4764857262830019912 ll
7: 7b 1a e8 ff 00 00 00 00 *(u64 *)(r10 - 24) = r1
8: bf a1 00 00 00 00 00 00 r1 = r10
9: 07 01 00 00 e8 ff ff ff r1 += -24
10: b7 02 00 00 12 00 00 00 r2 = 18
11: 85 00 00 00 06 00 00 00 call 6
12: b7 00 00 00 00 00 00 00 r0 = 0
13: 95 00 00 00 00 00 00 00 exit
llvm-objdump 输出的 bpf_prog 的内容其实就是 BPF 的字节码。
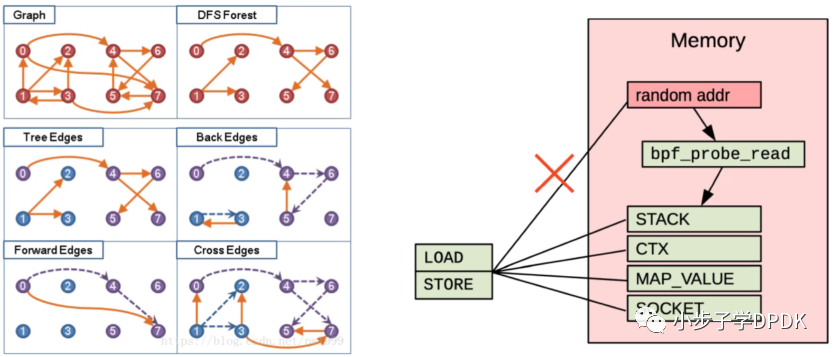
谈到字节码(byte code),我们首先想到的就是 jvm 虚拟机。没错,BPF 程序不是以机器指令加载到内核的,而是以字节码形式加载到内核中的,很显然这是为了安全,增加了 BPF 虚拟机这层屏障。在BPF程序加载到内核的过程中,BPF虚拟机会对 BPF 字节码进行验证并运行 JIT 编译将字节码编译为机器码。
用于加载和卸载 BPF 程序的用户态程序则可以由多种语言开发,既可以用 C 语言,也可以用 Python、Go、Rust 等。
BPF程序的开发方式
BPF 演进了这么多年,虽然一直在努力提高,但 BPF 程序的开发与构建体验依然不够理想。
为此社区也创建了像 BPF Compiler Collection BCC 这样的用于简化 BPF 开发的框架和库集合。
随着 BPF 应用得更为广泛,BPF 的移植性问题逐渐显现出来。
为什么 BPF 应用会有可移植性问题呢?Linux 内核在快速演进,内核中的类型和数据结构也在不断变化。不同的内核版本的同一结构体类型的字段可能重新排列、可能重命名或删除,可能更改为完全不同的字段等。对于不需要查看内核内部数据结构的 BPF 程序,可能不存在可移植性问题。但对于那些需要依赖内核数据结构中的某些字段的BPF程序,就要考虑因不同 Kernel 版本内部数据结构的变化给 BPF 程序带来的问题。
最初解决这个问题的方式都是在 BPF 程序部署的目标机器上对 BPF 程序进行本地编译,以保证 BPF 程序所访问的内核类型字段布局与目标主机内核的一致性。但这样做显然很麻烦:目标机器上需要安装BPF依赖的各种开发包、使用的编译器,编译过程也会很耗时,这让BPF程序的测试与分发过程十分痛苦。
为了解决 BPF 可移植性问题,内核引入 BTF(BPF Type Format) 和CO-RE (Compile Once – Run Everywhere) 两种新技术。BTF 提供结构信息以避免对 Clang 和内核头文件的依赖。CO-RE 使得编译出的 BPF 字节码是可重定位(relocatable)的,避免了 LLVM 重新编译的需要。使用这些新技术构建的 BPF 程序可以在不同 linux 内核版本中正常工作,无需为目标机器上的特定内核而重新编译它。目标机器上也无需再像之前那样安装数百兆的 LLVM、Clang 和 kernel 头文件依赖了。
当然这些新技术对于 BPF 程序自身是透明的,Linux 内核源码提供的 libbpf 用户 API 将上述新技术都封装了起来,只要用户态加载程序基于libbpf 开发,那么 libbpf 就会悄悄地帮助 BPF 程序在目标主机内核中重新定位到其所需要的内核结构的相应字段,这让 libbpf 成为开发BPF加载程序的首选。
下面将会介绍主流的 bcc 以及 libbpf 两种 eBPF 开发方式。
查看作者信息
