shell 编程(四):正则表达式
正则表达式
在 shell 脚本中要查找一个文本文件中的内容的时候一般会使用 grep 命令。但是假如所要查找的字符串具有一定的模式,并且该模式包含以下的信息:
- 字符类:表示在模式中的一个字符
- 数量限定符: 某一个字符在字符串中出现的次数
- 位置关系:表示上面的某些数量的字符出现的位置
使用一些特殊语法表示字符类、数量限定符和位置关系,然后用这些特殊语法和普通字符一起表示一个模式,这就是正则表达式(Regular Expression)。
正则表达式分类
正则表达式按照是否可扩展来说分为两种规范:Basic 规范以及 Extended 规范。两种规范在 shell 脚本中正好对应 grep 以及 egrep 两种查找文件中字符串的命令。
| 其实两种规范的语法格式大致相同,只不过对于 Basic 规范来说,遇到 **?+{} | ()** 这些符号时会被认为是普通字符,因此想要表示上述符号的特殊含义时需要加上 \ 转义字符即可。 |
如果用 grep 而不是 egrep ,并且不加-E参数,则应该遵照 Basic 规范来写正则表达式。
以下所介绍的语法格式是基于 Extended 规范的。
基本语法
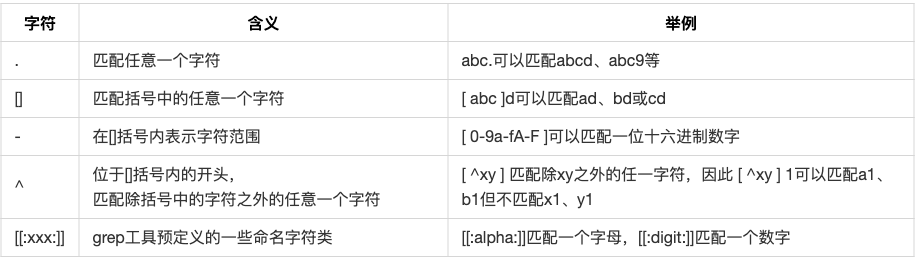
字符类
数量限定符
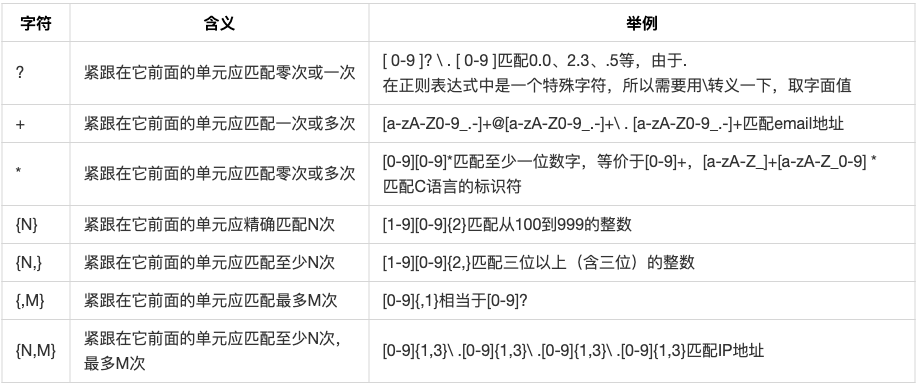
注意 grep 找的是包含某一模式的行,而不是完全匹配某一模式的行。再举个例子,如果文本文件的内容是
aaabc
aad
efg
查找 a* 这个模式的结果是三行都被找出来了
$ egrep 'a*' testfile
aabc
aad
efg
a* 匹配0个或多个a,而第三行包含0个a,所以也包含了这一模式。单独用 a* 这样的正则表达式做查找没什么意义,一般是把 a* 作为正则表达式的一部分来用。
位置限定符
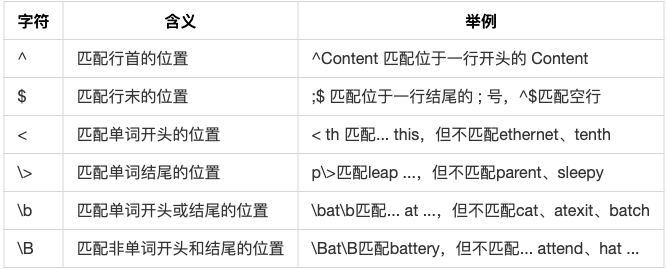
位置限定符可以帮助 grep 更准确地查找,例如可以用 [0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3} 来查找 IP 地址,找到这两行
192.168.1.1
1234.234.04.5678
如果用 \^[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}$ 查找,就可以把 1234.234.04.5678 这一行过滤掉了。
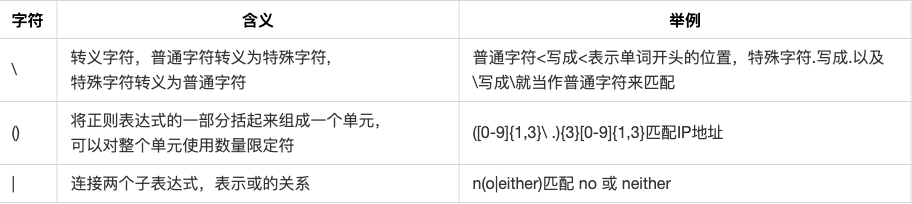
其它特殊字符
贪婪模式与非贪婪模式
正则表达式是有分贪婪模式和非贪婪模式两种的,一般默认的模式是贪婪模式。
在贪婪模式下是进行最大长度匹配,也就是所谓的贪婪匹配。
而非贪婪模式只是匹配到就近满足的地方就停止。
想要取消正则表达式的贪婪模式的话只需要在正则表达式中的量词后面加上 ?即可。
以下面的文本为例演示贪婪和非贪婪模式的区别:
<html><head><title>hello World</title></head>
<body>Welcome to the world of regexp</body></html>
在贪婪模式下使用如下的正则表达式进行匹配:
<.*>
匹配结果为:
<html><head><title>hello World</title></head>
<body>Welcome to the world of regexp</body></html>
在非贪婪模式下使用如下的正则表达式进行匹配:
<.*?>
匹配结果为:
<html>
<head>
<title>
</title>
</head>
<body>
</body>
</html>
查看作者信息
