Elasticsearch(一) 入门教程
Elasticsearch
Elasticsearch 是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
官方网址:https://www.elastic.co/cn/products/elasticsearch
Github:https://github.com/elastic/elasticsearch
对应的安装方式请看:Linux 安装 Elasticsearch
Elasticsearch快速入门
创建索引库
ES 的索引库是一个逻辑概念,它包括了分词列表及文档列表,同一个索引库中存储了相同类型的文档。它就相当于 MySQL中的表,或相当于 Mongodb 中的集合。
关于索引这个语:
- 索引(名词):ES是基于Lucene构建的一个搜索服务,它要从索引库搜索符合条件索引数据。
- 索引(动词):索引库刚创建起来是空的,将数据添加到索引库的过程称为索引。
下边介绍两种创建索引库的方法,它们的工作原理是相同的,都是客户端向ES服务发送命令。
1)使用 postman 或 curl 这样的工具创建:
put http://localhost:9200/索引库名称
同时设置如下的请求 json 数据:
{
"settings":{
"index":{
"number_of_shards":1,
"number_of_replicas":0
}
}
}
- number_of_shards:设置分片的数量,在集群中通常设置多个分片,表示一个索引库将拆分成多片分别存储不同的结点,提高了 ES 的处理能力和高可用性,入门程序使用单机环境,这里设置为1。
- number_of_replicas:设置副本的数量,设置副本是为了提高ES的高可靠性,单机环境设置为0.
示例:
本教程以创建课程信息的索引为例来介绍 ES 的入门使用,本教程使用 postman 来作为客户端工具。
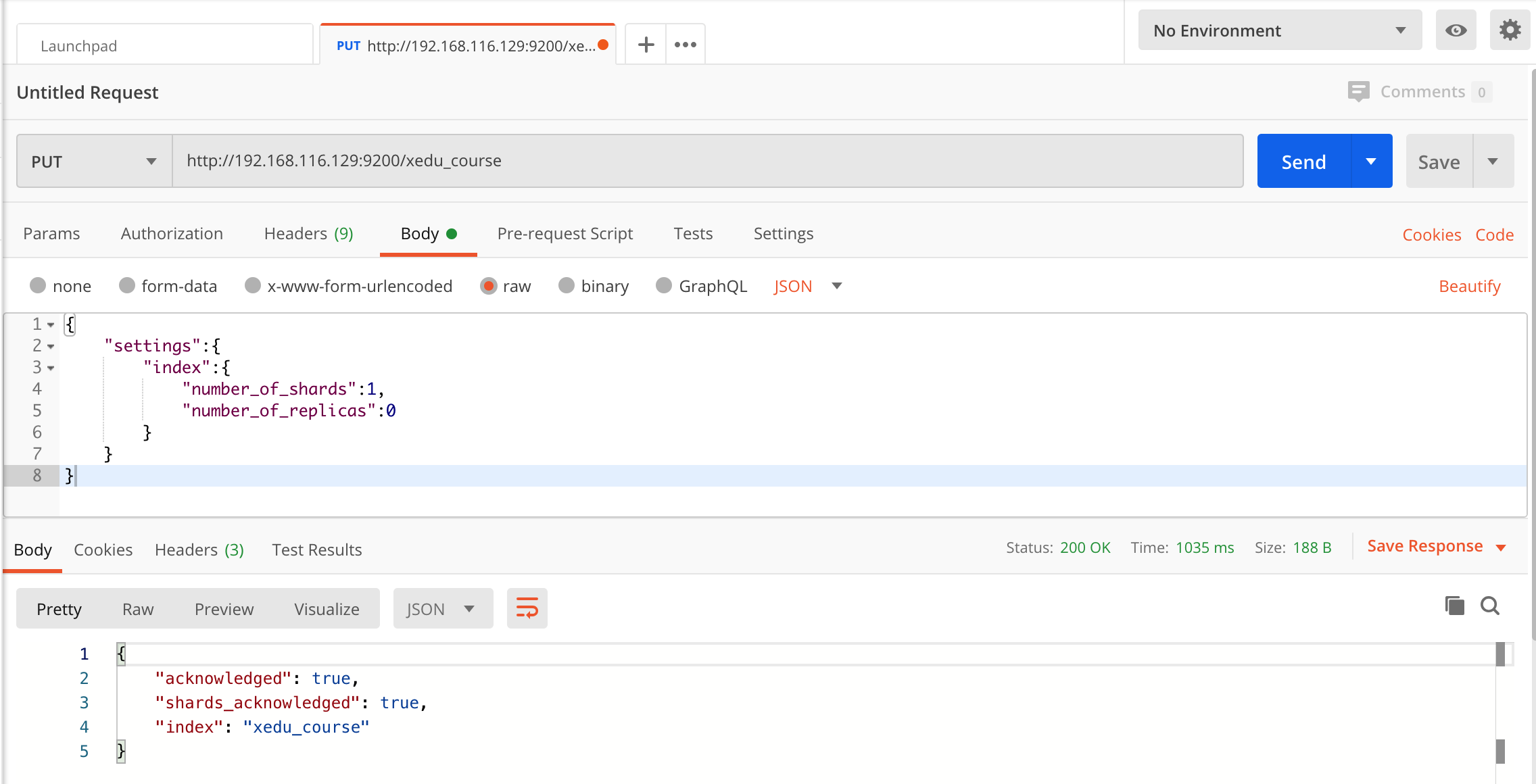
通过 head 插件也可以看到索引库的创建结果:
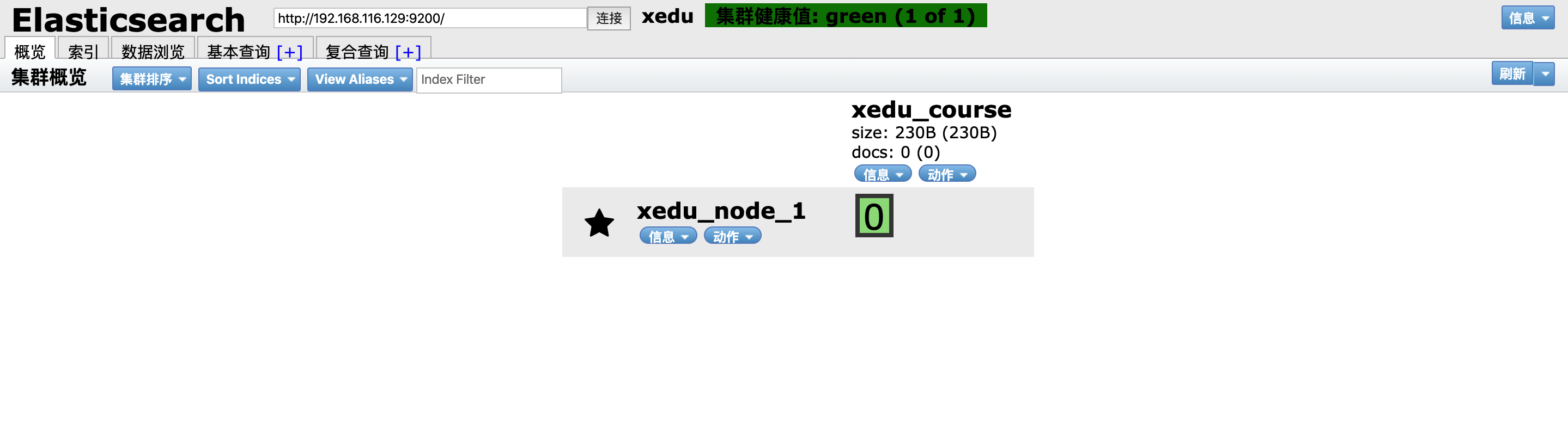
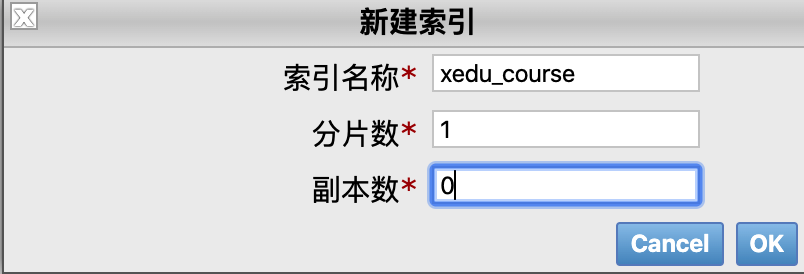
2)使用 head 插件创建
效果如下:
创建映射
在索引中每个文档都包括了一个或多个 field,创建映射就是向索引库中创建 field 的过程
下边是 document 和 field 与关系数据库的概念的类比:
文档(Document)----------------Row记录
字段(Field)-------------------Columns列
注意:
6.0之前的版本有 type(类型)概念,type 相当于关系数据库的表,ES 官方将在 ES9.0 版本中彻底删除 type。
上边讲的创建索引库相当于关系数据库中的数据库还是表?
1、如果相当于数据库就表示一个索引库可以创建很多不同类型的文档,这在ES中也是允许的。
2、如果相当于表就表示一个索引库只能存储相同类型的文档,ES官方建议在一个索引库中只存储相同类型的文档。
因此建议将索引库作为表来对待。
创建映射格式如下:
post http://localhost:9200/索引库名称/类型名称/_mapping
因为在 ES7 中已经弱化了类型的概念,因此现在创建一个映射的命令变为:
post http://localhost:9200/索引库名称/_mapping
我们要把课程信息存储到 ES 中,这里我们创建课程信息的映射,先来一个简单的映射,如下:
为 xedu_course 索引库创建对应的映射,共包括三个字段:
- name:课程名称
- description:课程描述
- studymondel:课程状态
post 请求:
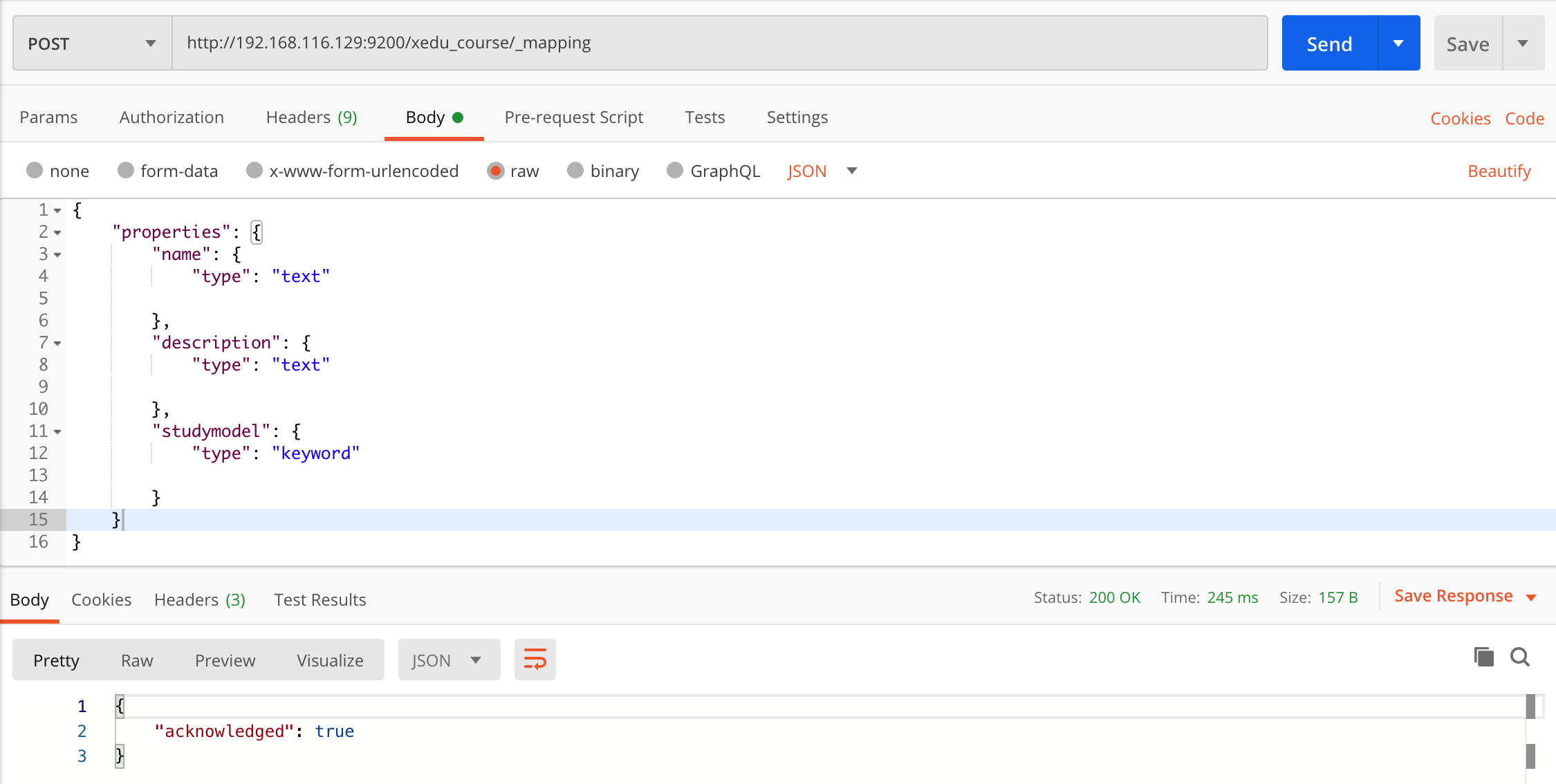
表示:在 xedu_course 索引库下创建映射。
在 head 中查看:
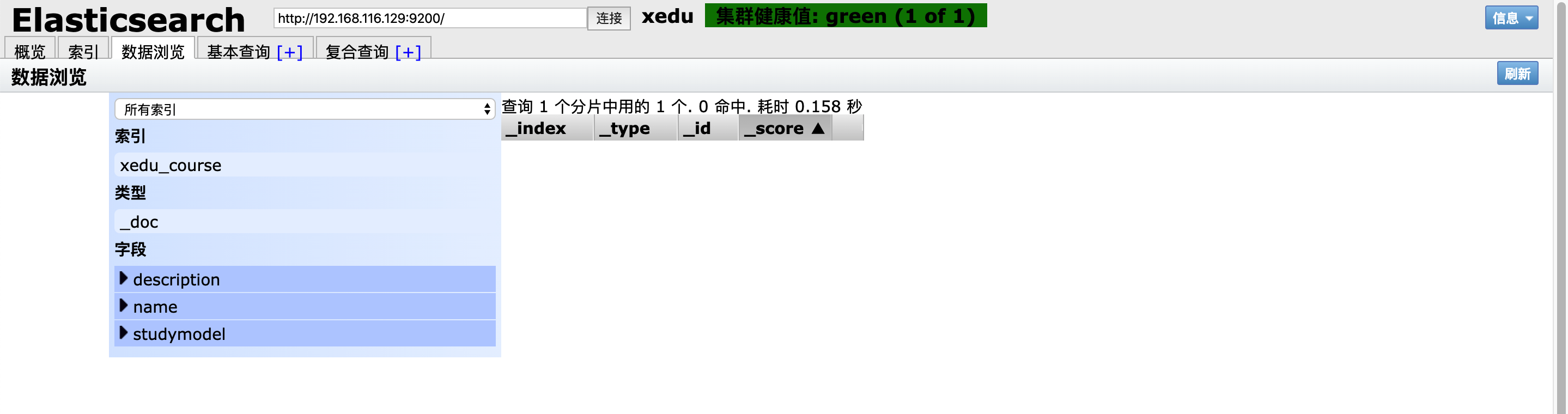
创建文档
ES 中的文档相当于 MySQL 数据库表中的记录。
发送格式:
put 或 Post http://localhost:9200/索引库名称/_doc/id值
# 如果不指定id值ES会自动生成ID
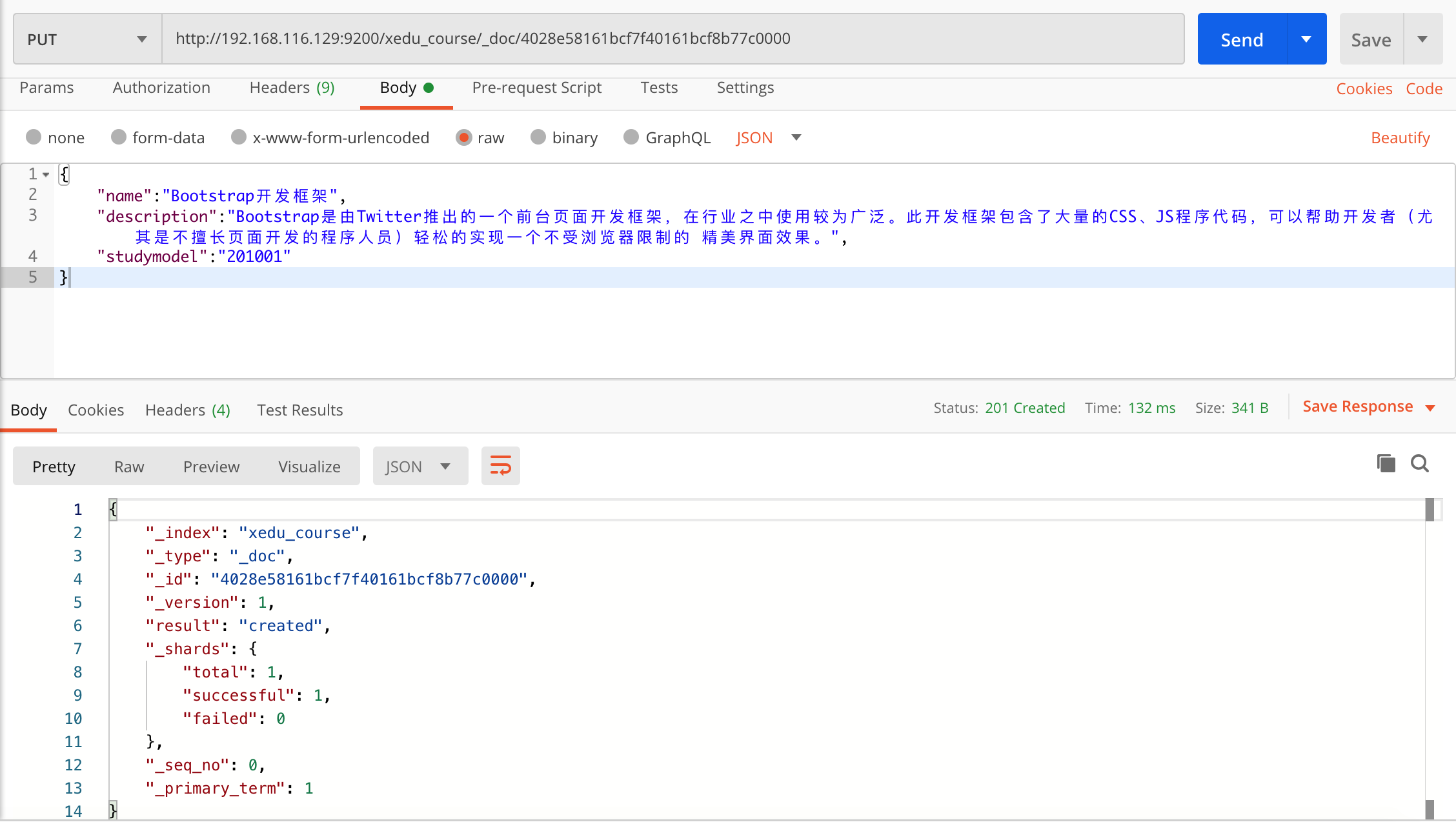
在 head 中查看:
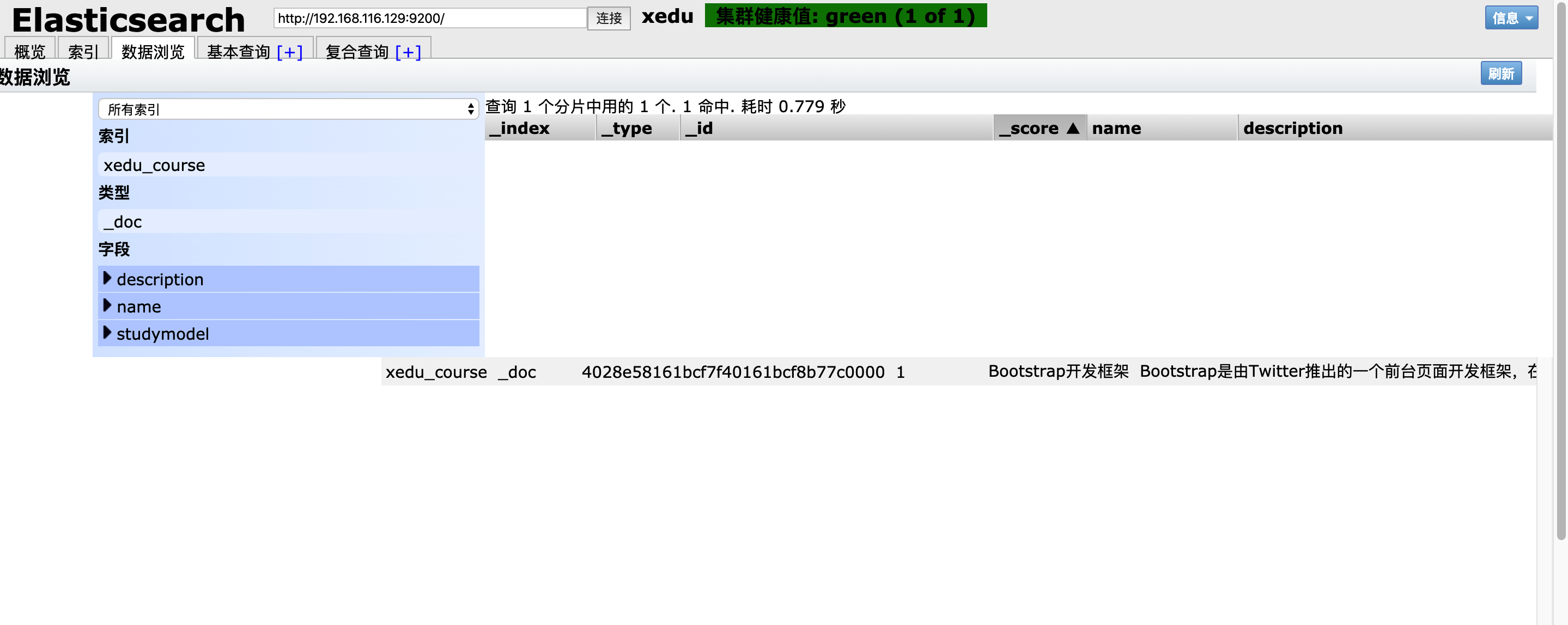
搜索文档
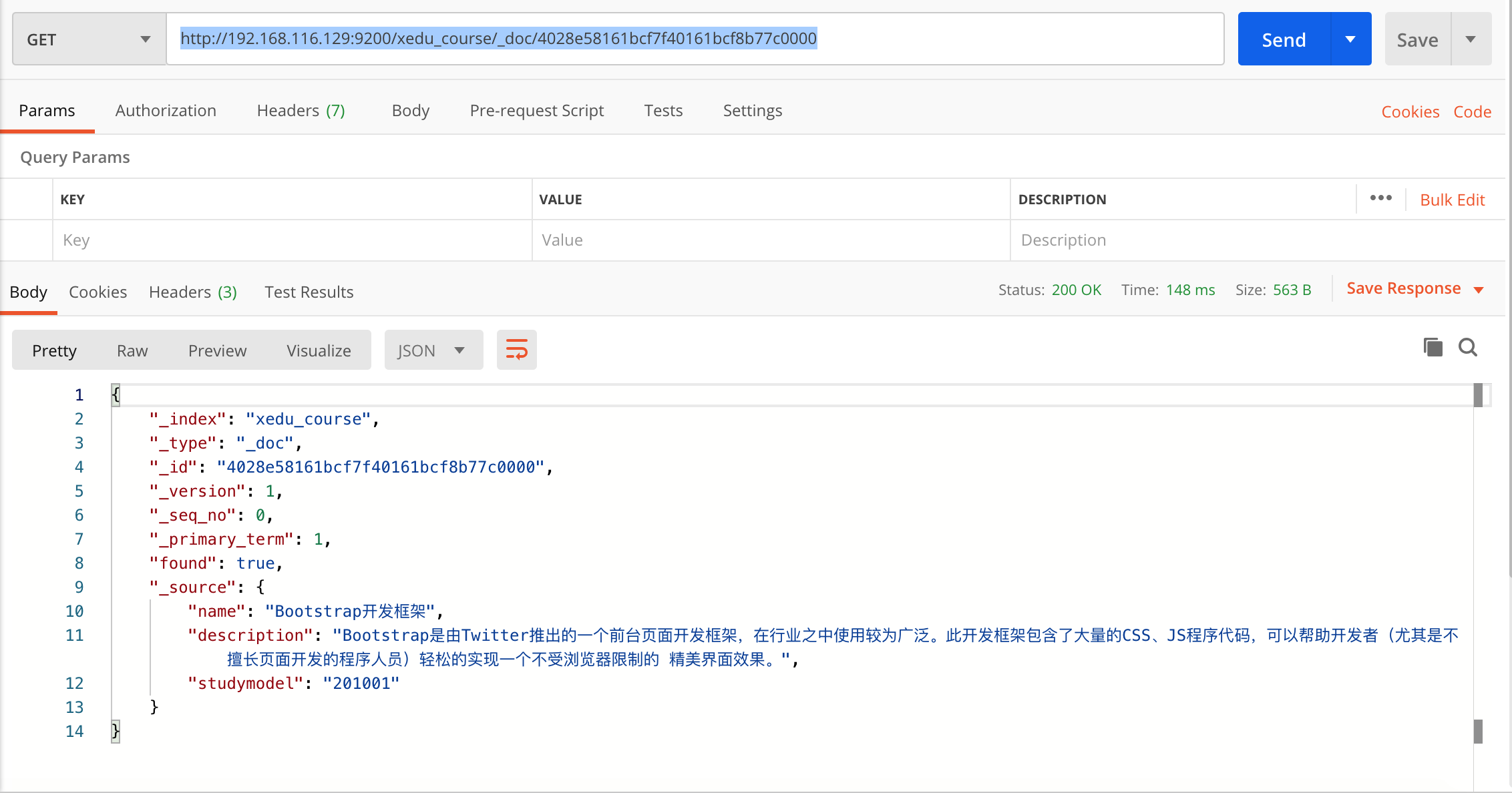
1、根据课程id查询文档
发送:
get http://192.168.116.129:9200/xedu_course/_doc/4028e58161bcf7f40161bcf8b77c0000
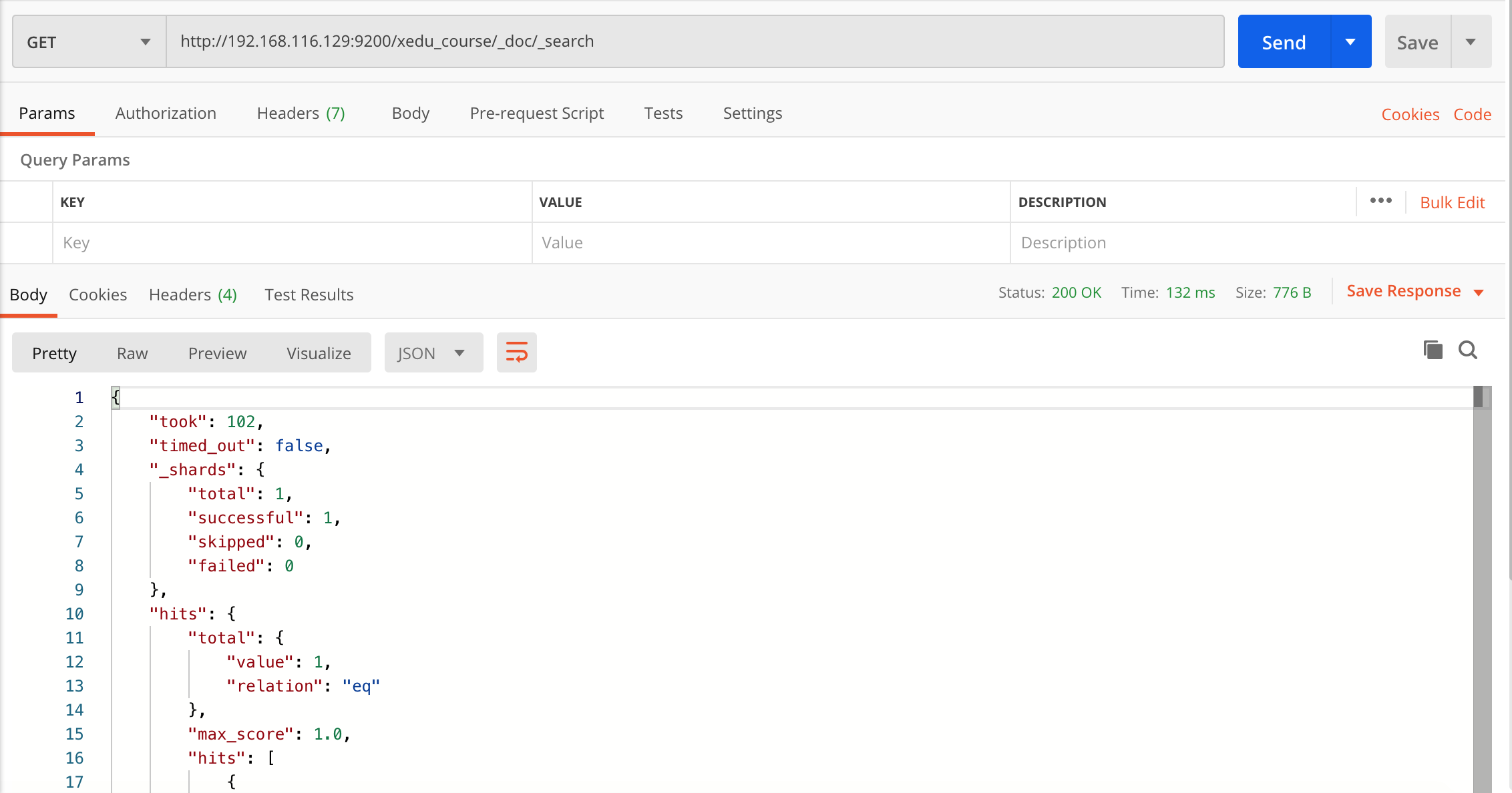
2、查询所有记录 发送
get http://192.168.116.129:9200/xedu_course/_doc/_search
3、查询名称中包括 bootstrap 关键字的的记录
发送:
get http://192.168.116.129:9200/xedu_course/_doc/_search?q=name:bootstrap
4、查询学习模式为 201001 的记录
发送
get http://192.168.116.129:9200/xedu_course/_doc/_search?q=studymodel:201001
分词器测试
在添加文档时会进行分词,索引中存放的就是一个一个的词(term),当你去搜索时就是拿关键字去匹配词,最终找到词关联的文档。
下面测试当前索引库使用的分词器:
post http://192.168.116.129:9200/_analyze
{"text":"测试分词器,后边是测试内容:spring cloud实战"}
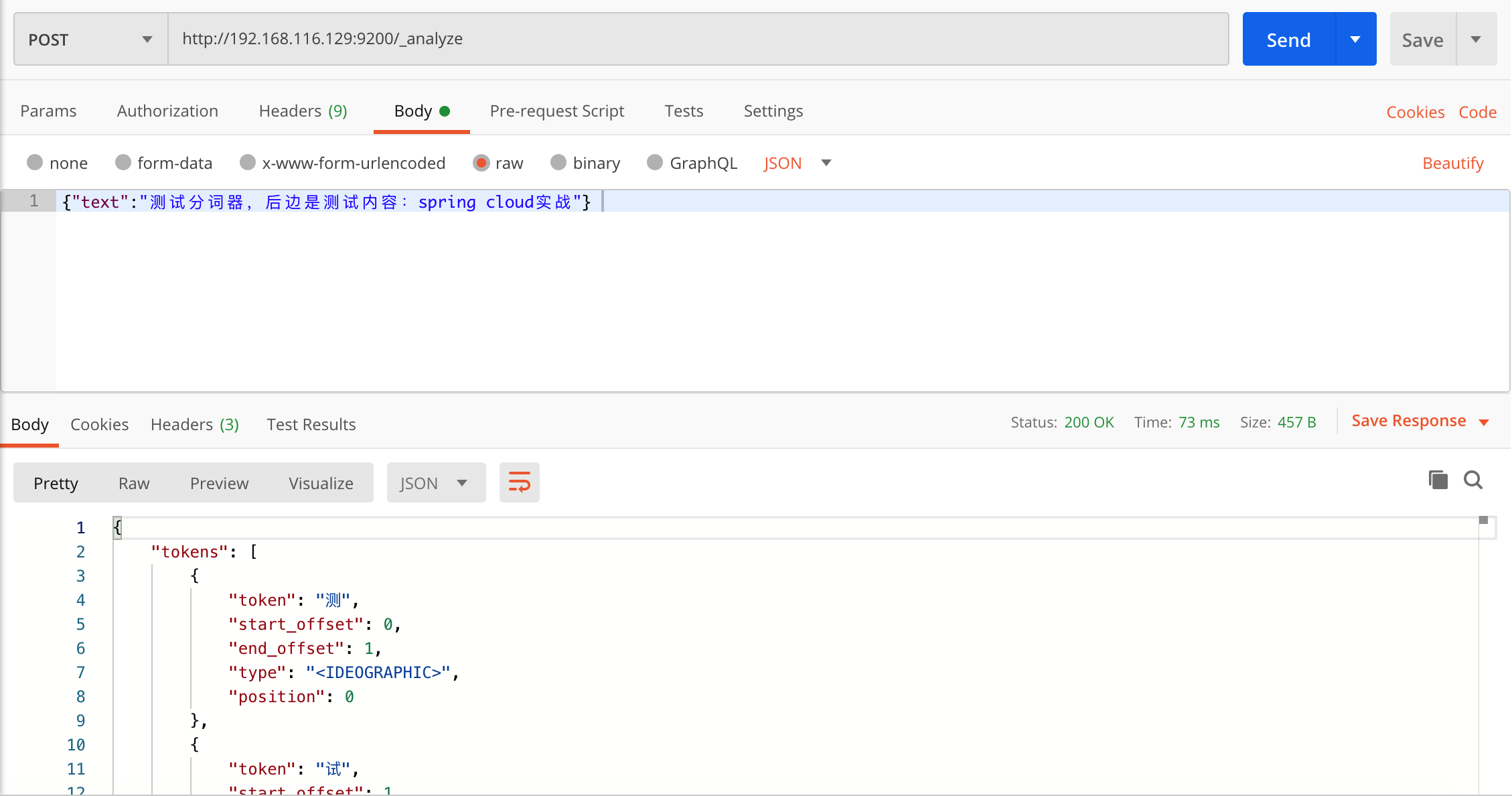
经过测试会发现分词的效果将 “测试” 这个词拆分成两个单字“测”和“试”,这是因为当前索引库使用的分词器对中文就是单字分词。
可以通过使用 IK 分词器来实现对中文分词的效果。
测试分词效果:
post http://192.168.116.129:9200/_analyze
{"text":"测试分词器,后边是测试内容:spring cloud实战","analyzer":"ik_max_word" }
ik 分词器有两种分词模式:
- ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、 华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
- ik_smart模式:会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
如果要让分词器支持一些专有词语,可以自定义词库。 iK分词器自带一个 main.dic 的文件,此文件为词库文件。在同级目录中新建一个 my.dic 文件(注意文件格式为utf-8)然后在其中自定义词汇,最后在配置文件中配置my.dic:
映射
映射维护方法
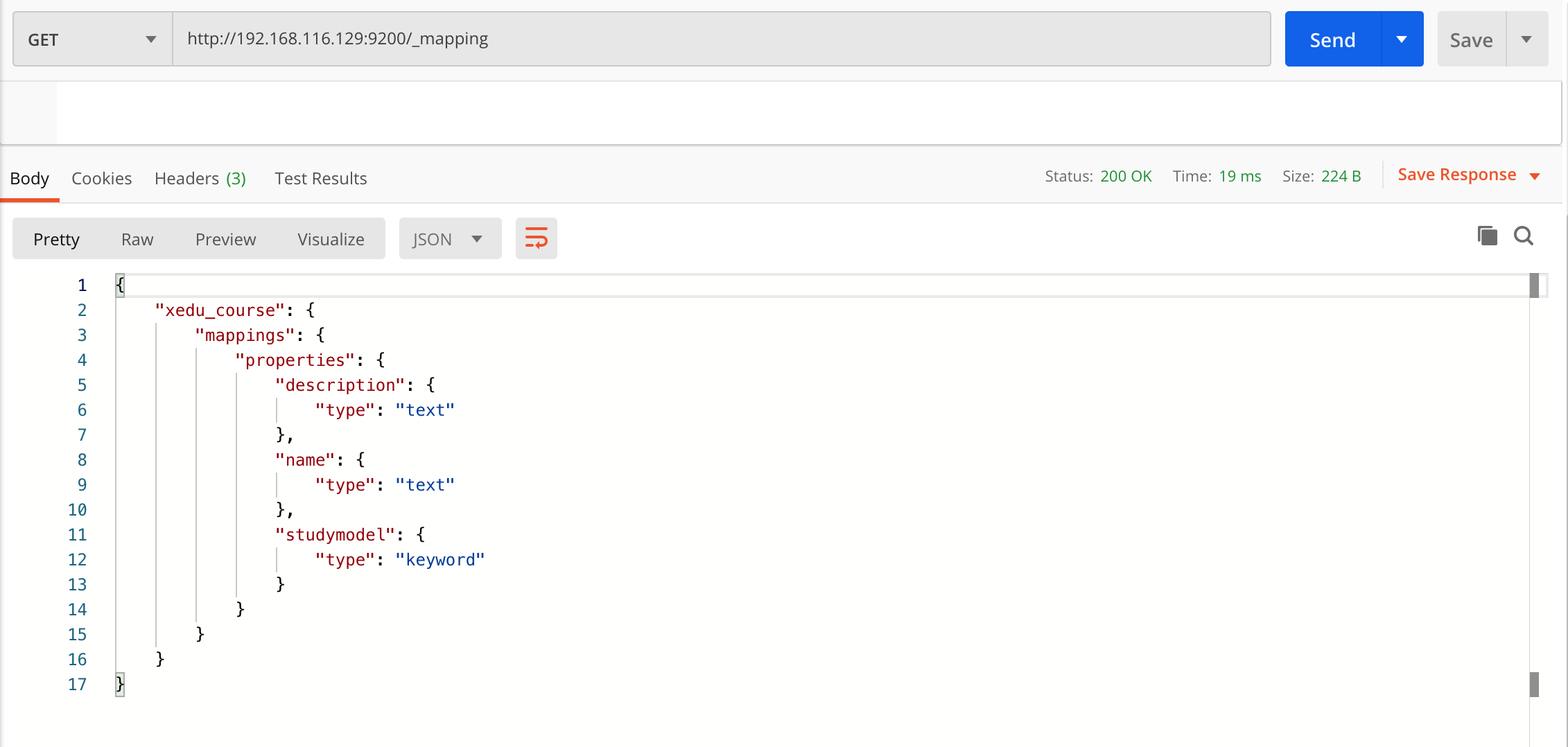
查询所有索引的映射:
get http://192.168.116.129:9200/_mapping
创建映射:
post http://localhost:9200/索引库名称/_mapping
更新映射
映射创建成功可以添加新字段,已有字段不允许更新。
删除映射
通过删除索引来删除映射。
常用映射类型
以下是 ES7 中所支持的核心的字段类型:

其中最主要也是最常用的类型就是 string,string 包括 text 和 keyword 两种类型:
text文本字段
text 表示正常的字符串数据,索引库需要对 text 字段的数据进行分词索引。下面介绍 text 类型中需要设置的属性:
analyzer
text 中通过 analyzer 属性指定分词器。
下边指定 name 的字段类型为 text,使用 ik 分词器的 ik_max_word 分词模式。
"name": {
"type": "text", "analyzer":"ik_max_word"
}
上边指定了 analyzer 是指在索引和搜索都使用ik_max_word,如果单独想定义搜索时使用的分词器则可以通过 search_analyzer 属性。
对于ik分词器建议是索引时使用 ik_max_word 将搜索内容进行细粒度分词,搜索时使用 ik_smart 提高搜索精确性。
"name": {
"type": "text", "analyzer":"ik_max_word", "search_analyzer":"ik_smart"
}
index
通过 index 属性指定是否索引。
默认为 index=true,即要进行索引,只有进行索引才可以从索引库搜索到。
但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将 index设置为 false。
store
store 表示是否在 source 之外存储,每个文档索引后会在 ES 中保存一份原始文档,存放在”_source”中,一般情况下不需要设置 store 为 true,因为在_source 中已经有一份原始文档了。
keyword关键字字段
keyword 表示的是关键字字段,其已经是关键字了,并不会对其进行分词索引。
通常搜索 keyword 是按照整体搜索,所以创建keyword 字段的索引时是不进行分词的,比如:邮政编码、手机号码、身份证等。
keyword 字段通常用于过虑、排序、聚合等。
date日期类型
日期类型不用设置分词器。
通常日期类型的字段用于排序。
format
通过 format 设置日期格式,比如:
下边的设置允许 date 字段存储年月日时分秒、年月日及毫秒三种格式。
{
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy‐MM‐dd HH:mm:ss||yyyy‐MM‐dd"
}
}
}
数值类型
下边是 ES 支持的数值类型
long
A signed 64-bit integer with a minimum value of -263 and a maximum value of 263-1.
integer
A signed 32-bit integer with a minimum value of -231 and a maximum value of 231-1.
short
A signed 16-bit integer with a minimum value of -32,768 and a maximum value of 32,767.
byte
A signed 8-bit integer with a minimum value of -128 and a maximum value of 127.
double
A double-precision 64-bit IEEE 754 floating point number, restricted to finite values.
float
A single-precision 32-bit IEEE 754 floating point number, restricted to finite values.
half_float
A half-precision 16-bit IEEE 754 floating point number, restricted to finite values.
scaled_float
A floating point number that is backed by a long, scaled by a fixed double scaling factor.
对于需要设置为数字类型的字段来说:
- 尽量选择范围小的类型,提高搜索效率
- 对于浮点数尽量用比例因子,比如一个价格字段,单位为元,我们将比例因子设置为100这在ES中会按分存储,映射如下:
"price": {
"type": "scaled_float", "scaling_factor": 100
},
由于比例因子为 100,如果我们输入的价格是 23.45则 ES 中会将 23.45 乘以 100 存储在 ES 中。
如果输入的价格是 23.456,ES会将 23.456 乘以100再取一个接近原始值的数,得出 2346。
使用比例因子的好处是整型比浮点型更易压缩,节省磁盘空间。
如果比例因子不适合,则从下表选择范围小的去用:

查看作者信息
